Codex 实战问答
我第一次认真用 Codex 的时候,也会下意识把它当成一个更会写代码的聊天窗口。用了一段时间之后,这个理解就不太够了。
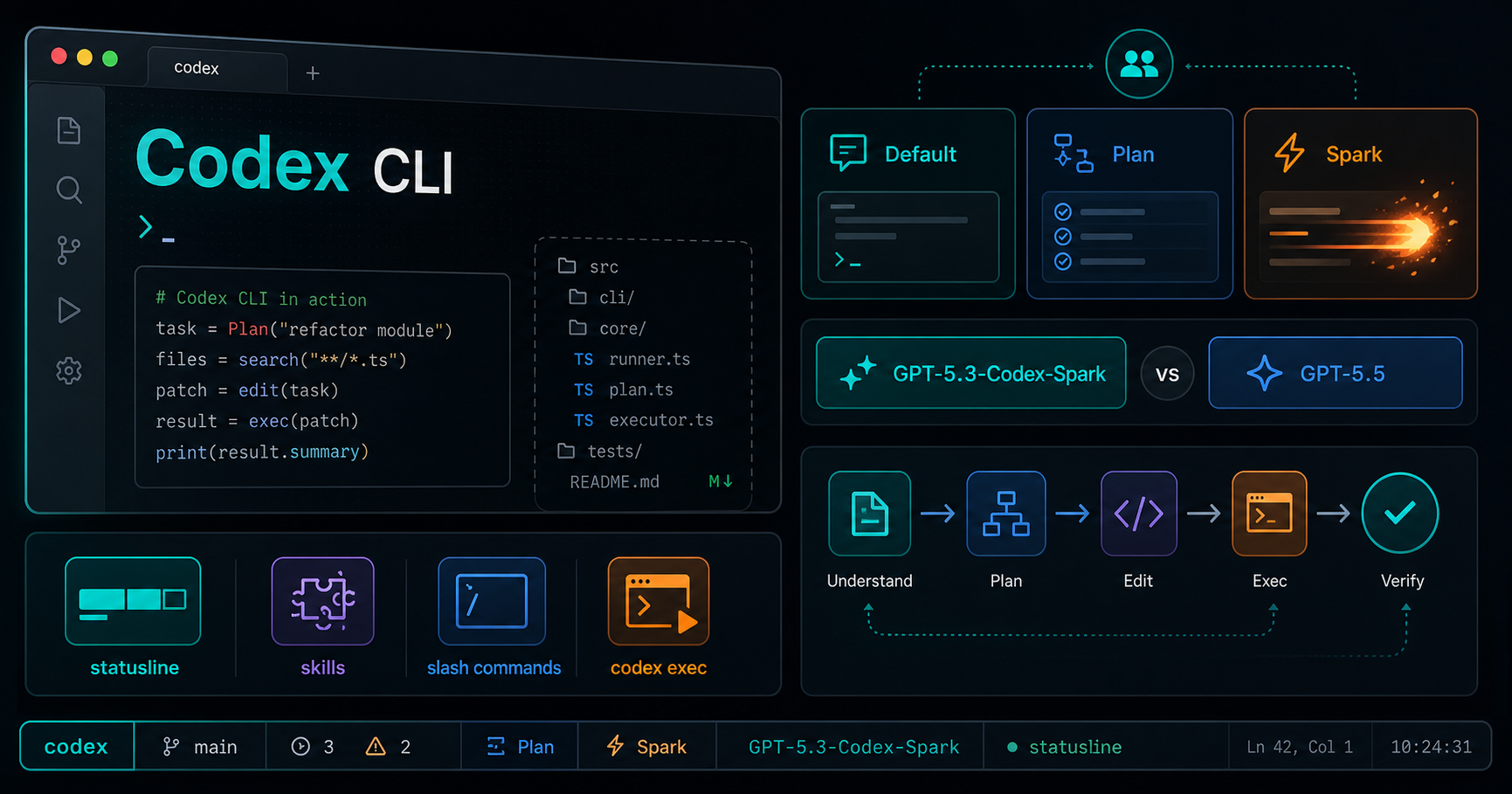
Codex 更像一个能进入工程目录工作的协作者。它可以读代码、改文件、跑命令、查 CI、写文档、开 PR,也可以通过 AGENTS.md、skills 和配置文件把一些固定流程沉淀下来。真正的变化不是“回答更聪明”,而是它开始接近一个能把工程任务推进到可验证状态的执行界面。
这篇文章用问答方式整理几个最近经常被问到的问题:collaboration mode 到底是什么,GPT-5.3-Codex-Spark 和 GPT-5.5 怎么选,限流怎么理解,statusline 怎么配,常用 slash command、codex exec 和 Codex SDK 适合什么场景。
古董级程序员,大厂出来后一直在创业公司,现在仍在一线做 AI 相关的工程。更完整的技术记录写在微信公众号「字与码」:工作经历、对新工具的看法,以及这些年踩过的坑,会不定期发在那里。若这篇对你有用,欢迎顺手关注。
Codex 和普通 ChatGPT 有什么区别?
普通 ChatGPT 更像回答问题的人;Codex 更像能进入项目目录工作的工程协作者。
这个差别在真实任务里会非常明显。CI 失败时,普通问答通常只能根据日志猜原因;Codex 可以拉代码、复现测试、定位失败、修复,再跑一遍测试。PR review 时,普通问答容易停在“这段代码看起来可以优化”;Codex 更适合按文件和行号指出行为风险、兼容性问题和缺失测试。
我现在更愿意把 Codex 看成一个“带工具和执行权限的工程代理”。问它问题当然可以,但更有价值的是把任务描述清楚,让它自己走完读代码、改文件、验证、总结这条链路。
collaboration mode 是什么?
collaboration mode 可以理解成 Codex 的协作方式:它决定 Codex 更偏主动执行,还是更偏先规划、先确认。
| 模式 | 适合场景 | 行为特点 |
|---|---|---|
| Default | 日常工程任务、修 bug、补测试、排查 CI、开 PR | 用户给出目标后,Codex 会优先自己推进;只有信息不足且贸然决定有风险时才停下来问 |
| Plan | 需求不清晰、存在多种方案、需要先选择路线的任务 | 更偏拆方案、列计划、等待确认;适合重构设计、复杂方案评审 |
我的习惯是:目标明确就用 Default,让 Codex 直接做到可验证状态;问题还没想清楚时,就直接说“先不要改代码,只给方案”。即使当前不是 Plan mode,也可以通过自然语言约束它。
先不要改代码,只分析这个接口是否有兼容性风险。
直接修复测试失败,跑完测试后总结改动。
只验证线上行为,不要写数据库,不要打印敏感信息。GPT-5.3-Codex-Spark 和 GPT-5.5 怎么选?
我不太建议只把 Spark 和同代 Codex 模型放在一起比。更实用的比较,是直接拿它和最强的 GPT-5.5 做取舍。
核心结论很简单:GPT-5.5 适合复杂和长链路任务,GPT-5.3-Codex-Spark 适合实时、低延迟、小范围迭代。Spark 的一个重要价值,是 research preview 期间拥有单独限流,不消耗标准 Codex rate limits。
| 维度 | GPT-5.5 | GPT-5.3-Codex-Spark |
|---|---|---|
| 定位 | 最强通用与专业工作模型,适合复杂推理、跨仓库、长任务 | 面向实时编码的超快模型,适合小范围快速协作 |
| 速度 | 更重,通常更慢但更稳 | 官方定位为超低延迟,适合近实时交互 |
| 任务类型 | 系统性重构、复杂排障、跨服务设计、深度 review | 改一个函数、补一个测试、调 UI、解释局部代码、快速试错 |
| 限流 | 走标准 Codex / ChatGPT 使用限制或账户额度 | preview 期间单独限流,不计入标准 rate limits |
所以选择规则也很直接:需要“稳、深、长”,用 GPT-5.5;需要“快、短、马上看结果”,用 GPT-5.3-Codex-Spark。Spark 不应该被理解成最强模型,而应该被理解成实时协作模型和额外限流池。
套餐和限流应该怎么理解?
Codex 的限流不是简单按“消息条数”计算。任务大小、代码库规模、上下文长度、工具调用、长时间运行、执行位置,都会影响消耗。小脚本可能只消耗很少额度,大仓库长任务会明显重很多。
| 套餐口径 | Codex 使用 | Spark 相关差异 | 实践建议 |
|---|---|---|---|
| Free 免费 | 通常适合体验,额度较低 | Spark 是否可用以账户实际模型列表为准 | 适合小任务,不适合连续工程工作 |
| Plus,约 20 美金/月 | 适合个人日常使用,但长任务仍可能碰到额度 | 如果账户可用 Spark,它的 preview 限流独立于标准 Codex 限流 | 适合日常开发和中小任务 |
| Pro,常见高阶套餐口径约 100/200 美金/月 | 更适合高频和长时间 Codex 使用 | Spark 单独限流的价值在 Pro 场景更明显 | 适合把 Codex 当作日常工程协作者 |
| Business / Enterprise / Edu | 适合团队使用,有更明确的数据控制和管理能力 | 模型可用性和限流通常由 workspace 与管理员配置决定 | 适合纳入 CI、review、发布和文档流程 |
什么时候会被限流?连续高频对话、大仓库长上下文、多个长任务并行、频繁自动化调用、模型处于高峰期或 preview 容量紧张时,都可能触发限流、排队或模型暂不可用。Spark 的单独限流不等于无限使用,它只是和标准 Codex 限流分开。
statusline 为什么重要?
statusline 是 Codex CLI 底部状态栏。它的价值不是装饰,而是让你随时知道当前模型、推理强度、目录、Git 分支、上下文剩余量、限流窗口、Codex 版本和任务进度。
我推荐至少放这些字段:
[tui]
status_line = [
"model-with-reasoning",
"current-dir",
"git-branch",
"run-state",
"permissions",
"approval-mode",
"context-remaining",
"five-hour-limit",
"weekly-limit",
"codex-version",
"thread-title",
"task-progress"
]里面最关键的几项,是 model-with-reasoning、current-dir、git-branch、permissions、approval-mode 和 context-remaining。
很多误操作并不是模型不知道怎么做,而是用户和 Codex 对当前状态的认知不一致。你以为它在只读模式,它其实有写权限;你以为在目标仓库,它其实在另一个目录;你以为当前是强模型,它实际跑在轻量模型。statusline 的作用就是把这些隐性状态摆在眼前。
skill 应该沉淀什么?
skill 是把反复出现的流程固化下来的一种方式。凡是连续出现三次以上、步骤固定、容易遗漏细节的流程,都值得做成 skill。
我现在会把这些内容做成 skill:
| 能力类型 | 适合沉淀的内容 |
|---|---|
| 官网测试 | API、搜索、执行、计费、用户 API key 查询等固定流程 |
| 产品发布 | release tag、测试环境 PR、线上发布 PR 的分支规则 |
| 工作总结 | 按时间窗口汇总 commit、issue、PR、文档、会议和会话 |
| 文档处理 | 创建、读取、更新飞书文档,固定 XML / Markdown 规范 |
| 博客写作 | 文章 frontmatter、文风、头图路径、构建命令 |
| 图片生成 | 需要生成位图素材时的风格、尺寸和禁忌 |
skill 里最重要的不是写一堆背景知识,而是写清楚何时触发、怎么做、哪些文件要读、哪些风险不能踩。它应该像一个给未来自己的操作手册,而不是一篇解释性长文。
常用 slash command 怎么用?
Codex 的 slash command 很多,但日常最常用的是下面这些。
| 命令 | 作用 | 最佳实践 |
|---|---|---|
/ide | 把 IDE 当前打开文件、选区和编辑器上下文加入下一轮 prompt | 正在看某段代码,希望 Codex 不用重新搜索就理解当前上下文时使用 |
/memories | 配置 memory 注入和生成 | 适合长期偏好,不要存密钥、密码、客户隐私或临时事实 |
/goal | 设置、查看、暂停、恢复或清理长期目标 | 大任务、跨多轮排查、需要持续跟踪完成度时使用 |
/fork | 从当前会话分叉一个新线程 | 探索另一个方案,但不想污染主线会话时使用 |
/side | 开启临时侧边对话 | 问一个小问题或验证一个概念,不影响主会话上下文 |
/raw | 切换原始 scrollback 模式 | 长日志、命令输出、需要复制终端内容时使用 |
/personality | 调整 Codex 的沟通风格 | 让回复更简洁或更解释型,不改变工程规则 |
/status | 查看当前 session 配置和 token 使用 | 确认模型、审批策略、可写目录、上下文剩余量 |
/compact | 压缩长会话上下文 | 上下文剩余量低、任务还没完成时使用 |
/diff | 查看当前 Git diff | 提交前确认 Codex 改了什么,包括未跟踪文件 |
这里面我最常用的是 /goal、/side 和 /diff。大任务先设 goal,旁路问题用 side,提交前一定看 diff。
/goal 指定和不指定有什么区别?
不指定 goal 时,Codex 主要围绕当前用户消息工作。短任务、一次性问题、边界清楚的修改,不指定 goal 完全没问题。
指定 goal 后,Codex 会有一个持久目标,可以在多轮对话中围绕它推进,并跟踪预算、进度和完成状态。它更适合“今天要完成一整条工作链路”的场景,例如排查问题、修复、测试、提交、开 PR、写说明。
目标:把搜索服务的索引增量更新问题修复到可上线状态。
完成标准:代码已提交,测试通过,PR 已创建,线上验证方案已写清楚。经验规则是:如果任务可以在十分钟内完成,不一定需要 goal;如果任务需要跨多个仓库、多轮验证,或者中途可能被打断,应该设置 goal。
什么时候需要 /fork?
/fork 的核心价值是保留主线,同时探索分支。它不是普通的新会话,而是从当前上下文复制出一个新线程。
我会在这些情况用它:
- 同一个问题存在两个修复方案,需要分别试验。
- 主线正在做稳定修复,临时想探索一个激进重构。
- 需要把当前上下文交给另一个方向,但不想让主线混入无关讨论。
如果只是问一个小问题,用 /side 更轻。
怎么让 Codex 记住一些事情?
“记住”有几种层次,应该按稳定性选择载体。
| 要记住的内容 | 推荐载体 | 原因 |
|---|---|---|
| 仓库规则、测试命令、分支规范 | AGENTS.md | 和代码仓库绑定,团队成员和 Codex 都能读到 |
| 个人默认模型、statusline、sandbox、MCP | ~/.codex/config.toml | 属于个人工作环境配置 |
| 固定流程,例如发布、官网测试、日报 | skill | 流程化、可复用,能包含步骤和风险提示 |
| 长期个人偏好 | /memories | 适合偏好类信息,但要避免敏感数据 |
| 一次任务中的临时约束 | 当前 prompt 或 /goal | 只在当前任务有效,不污染长期记忆 |
不要让 Codex 记住密钥、密码、生产数据库凭据、客户隐私、一次性 token、内部未公开商业信息。需要用时放在环境变量或权限受控的配置里,并要求 Codex 不打印。
codex exec 适合什么?
codex exec 是非交互模式,适合把 Codex 放进命令行、CI、定时任务和流水线里。它不是进入 TUI 对话,而是给 Codex 一个明确任务,让它运行后输出结果。
几个典型例子:
# 只读分析当前仓库测试失败原因
codex exec --sandbox read-only --ask-for-approval never \
"分析最近一次 pytest 失败原因,只输出结论和涉及文件"
# 允许在工作区内改文件,用于自动修复小问题
codex exec --sandbox workspace-write --ask-for-approval never \
"修复 lint 失败,保持改动最小,并说明改了哪些文件"
# 根据 git log 生成发布说明草稿
git log --oneline v1.2.0..HEAD | codex exec --sandbox read-only --ask-for-approval never \
"根据输入生成中文 release notes"非交互模式的 prompt 要更窄,权限要更保守。能只读就只读;必须改文件时再给 workspace-write;不要在无人值守任务里默认使用危险全权限。
0.131.0 里的 /pets 有什么用?
/pets 是 Codex CLI 0.131.0 引入的终端宠物选择入口。它会在 Codex TUI 里展示一个 ambient pet,也就是一个不影响主聊天流的陪伴式状态元素。
这个功能主要服务于体验和状态感知,不改变模型能力,也不会让任务执行更快。宠物 sprite 会随任务状态变化,比如运行中、等待输入、review ready、失败等。它可以通过 /pets 关闭;终端能力不支持时也可能自动禁用。
我对它的看法比较简单:如果你经常长时间开着 Codex TUI,它能让状态反馈更轻松;如果你用 tmux、终端不支持图片,或者喜欢极简界面,关掉就好。
0.131.0 里还有哪些值得注意的变化?
0.131.0 的核心变化不是单一功能,而是 TUI 更像一个可长期工作的工程控制台。
第一,状态栏显示 blended token usage。它更接近用户真正关心的消耗口径,避免把 cached input tokens 也直接算进状态栏数字里,造成“为什么 token 看起来突然暴涨”的误解。
第二,session 控制和状态展示更丰富。状态栏和 /status 可以更清楚地展示权限模式、approval mode、run-state、task-progress、effective workspace roots 等信息。
第三,service-tier slash commands 数据驱动化。以前 /fast 更像硬编码命令,现在由模型 catalog 暴露的 service_tiers 决定。当前模型支持哪些 tier,TUI 就显示哪些对应命令;不支持就不显示。
第四,effective workspace roots 展示更准确。它表示最终生效的工作区目录集合,而不是配置里某一层的原始值。这个变化对安全很重要:当你以为 Codex 只能改当前仓库,但 effective workspace roots 里还有额外目录时,实际权限边界比你以为的大。
Codex SDK 能干什么?
Codex SDK 的价值,是把“人手动打开 Codex 做任务”进一步变成“程序可编排的工程工作流”。它适合构建可重复、可审计、可观察的单 agent 或多 agent 软件交付流程,而不是只在终端里临时对话。
可以从两个方向理解:
| 方向 | 它解决什么问题 | 适合场景 |
|---|---|---|
| Codex Python SDK | 用代码控制 Codex 运行、turn 路由、approval mode 等 | 把 Codex 集成进内部脚本、服务端流程、自动化工具 |
| OpenAI Agents SDK + Codex MCP Server | 把 Codex CLI 暴露为 MCP server,再由 Agents SDK 编排一个或多个 agent | 多角色研发流水线、自动化改代码、评审、测试、交付 |
和 codex exec 相比,SDK 更适合有状态、多角色、可观察、可复用的流程。比如 CI 失败后,Planner 负责判断问题范围,Developer 负责最小修复,Reviewer 负责审查风险,Tester 负责跑验证,最后把 traces、artifacts 和人工审批点留存下来。
如果只是单次任务,codex exec 就够了;如果你要把 Codex 接进长期运行的研发系统,才需要 SDK 或 Agents SDK 这一层。
我的使用原则
最后总结一下我自己的规则:
- 把 Codex 当成工程协作者,而不是只会回答问题的聊天框。
- 小任务用 Spark 提速,大任务用 GPT-5.5 保质量。
- Spark 的核心价值之一是单独限流池,但它不是无限额度。
- 用 statusline 随时确认模型、目录、分支、上下文和权限。
- 把高频流程沉淀成 skill,把仓库规则写进
AGENTS.md。 - 长任务设置
/goal,分支探索用/fork,旁路问题用/side。 - 自动化场景用
codex exec,但要收窄 prompt 和权限。 - 任何涉及生产、资金、隐私、删除、发布的操作,都要保留人工确认点。
Codex 的真正价值,不是让你少打一段代码,而是把很多“读上下文、试方案、跑验证、写说明”的工程循环压缩成一个更稳定的协作流程。它仍然需要人定目标、把风险关住、审最终结果;但只要边界设好,它已经足够进入日常开发工作流了。
参考资料
- OpenAI Codex CLI slash commands
- OpenAI Codex non-interactive mode
- OpenAI Codex best practices
- Introducing GPT-5.3-Codex-Spark
- Using Codex with your ChatGPT plan
- OpenAI Codex Release 0.131.0
- Creating multi-agent workflows
微信公众号
欢迎关注「字与码」
如果这篇文章对你有用,也欢迎在微信里继续关注后续更新。

X / Twitter
关注 @ax2_zicode
更即时的技术观察、新文章提醒和一些短想法会发在 X 上。