
从 Prompt 到 Context Engineering:Agent 开发真正难的是给上下文
古董级程序员,大厂出来后一直在创业公司,现在仍在一线做 AI 相关的工程。更完整的技术记录写在微信公众号「字与码」:工作经历、对新工具的看法,以及这些年踩过的坑,会不定期发在那里。若这篇对你有用,欢迎顺手关注。
很多 Agent 的问题,看上去像模型不够聪明,细看却是它拿到的现场材料太糟。
用户说“修一下 CI”,系统把整段聊天历史、README、最近十次工具输出、仓库目录树、旧任务摘要、若干条检索结果全塞进去。模型当然可以读,但它并不知道哪一段是当前真实失败,哪一段是上周的猜测,哪一个日志来自最新提交,哪一个约束绝对不能违反。于是它开始像一个被丢进资料室的新人,翻到什么就信什么。
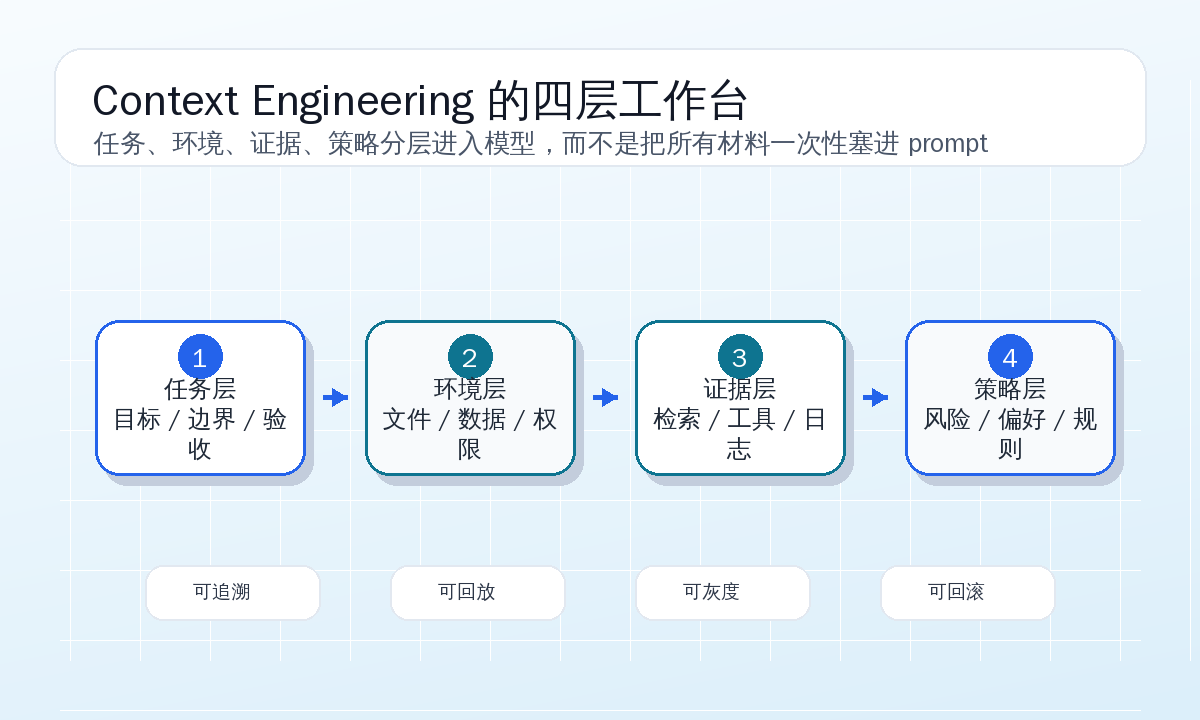
我现在更愿意把 Agent 开发的主战场叫 Context Engineering。Prompt 仍然重要,但它只是语气、角色和少量原则。真正决定生产效果的,是每一步给模型准备什么上下文、按什么优先级摆放、怎么记录来源、如何压缩、如何回放,以及什么时候明确告诉模型“这里有冲突,不要自己猜”。
这篇不讲概念清单,直接用一个可复制的案例展开:一个代码修复 Agent,原来只能凭 CI 失败日志乱猜,后来被改造成能够从 CI 失败一路定位、修改、验证并创建 PR 的上下文包流水线。
事故现场:CI 红了,Agent 却改错了地方
先设一个普通到不能再普通的项目。仓库叫 demo-billing-service,不是任何真实公司项目。它有一个 Node 后端,CI 里跑 npm test 和 npm run lint。某次提交后,GitHub Actions 里一个测试失败:
FAIL tests/invoice-discount.test.ts
applyDiscount
expected 9900 to equal 9000
Received invoice:
subtotal: 10000
coupon: "WELCOME10"
customerType: "new"用户给 Agent 的输入也很短:
{
"task": "CI 失败了,帮我修好并开一个 PR",
"repo": "demo-billing-service",
"run_id": "ci-20260615-1842",
"branch": "feature/coupon-refactor"
}旧版 Agent 的上下文构造方式很粗暴。它把最近十轮对话、CI 完整日志、仓库 README、src/ 下所有文件名、git diff、测试文件、工具说明拼成一段长 prompt。系统提示词里写了“你是资深工程师,请谨慎修改”。这类 prompt 在演示时很像那么回事,真实跑起来会出几个稳定的坏毛病。
它会被旧对话带偏。比如历史摘要里有一句“上次讨论过会员价逻辑可能要调整”,模型就会去改 memberPrice.ts。它会被日志噪声带偏。完整 CI 日志里有 300 行依赖 warning,模型会误判为依赖版本问题。它还会被 README 带偏。README 里写的本地测试命令是旧的 npm run test:unit,当前项目已经改成 npm test。
最糟的一次,Agent 把断言从 9000 改成 9900。CI 绿了,但业务错了。测试原本在保护“新用户欢迎券打九折”,模型却把测试改成适配错误实现。它不是故意偷懒,它只是没有得到足够明确的任务边界:本次目标是修实现,不是放宽测试;失败测试是证据,不是待修改对象;旧对话只是背景,不该压过当前 CI。
Context Engineering 要解决的,正是这种“材料看似很多,现场其实很乱”的问题。
第一个改造:把输入从 prompt 变成 context package
我不会从“写更好的系统提示词”开始,而是先定义 Agent 每一步能接收的上下文包。上下文包不是给人看的报告,它是给模型和审计系统共同使用的任务现场。
代码修复场景里,第一版结构可以很朴素:
{
"package_id": "ctx-ci-fix-01HZX",
"package_version": "code_fix_context_v1",
"objective": {
"user_goal": "修复 CI 失败并创建 PR",
"success_criteria": [
"失败测试重新通过",
"不删除或跳过测试",
"不扩大折扣业务行为",
"PR 描述包含修改原因和测试结果"
],
"latest_user_message_id": "msg-1842"
},
"environment": {
"repo": "demo-billing-service",
"branch": "feature/coupon-refactor",
"base_branch": "main",
"ci_run_id": "ci-20260615-1842",
"workspace_status": "clean"
},
"evidence": [],
"constraints": [],
"tool_budget": {
"max_shell_commands": 20,
"max_file_reads": 30,
"requires_human_approval_for_push": true
}
}这个结构看起来不如一大段 prompt 有“智能味”,但它有一个关键优点:每个字段都有责任。objective 管目标,environment 管当前状态,evidence 管证据,constraints 管边界,tool_budget 管动作成本。模型后面做错事时,我们可以问得很具体:目标错了,环境旧了,证据缺了,还是约束太弱。
旧版 prompt 最大的问题是所有东西混在一起。用户最新输入、模型上一步猜测、README、工具报错都以自然语言并排出现。模型当然会读,但它无法稳定地区分“事实”“猜测”“历史偏好”“当前约束”。上下文包的第一件事,就是把这些东西拆开。
CI 日志不能整坨塞进去
CI 失败日志是本案最重要的证据,但也最容易污染上下文。完整日志通常有安装依赖、缓存恢复、lint 输出、测试进度、warning、失败堆栈。旧版 Agent 直接塞全文,结果模型把 warning 当成根因。
改造后,CI 工具不返回整段文本,而返回结构化摘要和原文引用:
{
"type": "ci_failure",
"source": "github_actions",
"run_id": "ci-20260615-1842",
"collected_at": "2026-06-15T10:42:31Z",
"command": "npm test",
"status": "failed",
"primary_failure": {
"test_file": "tests/invoice-discount.test.ts",
"test_name": "applyDiscount applies WELCOME10 for new customers",
"assertion": "expected 9900 to equal 9000",
"stack_top": "tests/invoice-discount.test.ts:28:22"
},
"noise": {
"warnings_count": 37,
"warnings_sample": ["deprecated package warning"],
"classified_as": "non_blocking"
},
"raw_log_ref": "artifact://ci-20260615-1842/log.txt#L810-L846",
"confidence": 0.94
}这里有几个细节很重要。
primary_failure 只放最接近失败的事实,不替模型下业务结论。它说“9900 不等于 9000”,不说“折扣算法错了”。noise 不是删除 warning,而是标注它们被判断为非阻塞。raw_log_ref 保留回放入口,后续如果摘要器误判,可以回到原文。
上下文工程不是把日志压成一句话,而是把日志压成可验证的证据。压缩必须保留三样东西:来源、适用范围、回查路径。缺一个,摘要就容易变成无出处的“二手事实”。
文件选择:不要让模型在仓库里盲逛
拿到失败测试以后,Agent 需要读文件。旧版做法是让模型自己 ls、grep、打开一堆文件。这样也能工作,但成本高,而且模型很容易被相似名字带偏。
更稳定的方式是先用一个轻量检索器生成候选文件,再把候选关系写进上下文包。比如从测试堆栈、import、最近 diff 和代码搜索得到:
{
"type": "file_candidates",
"generated_by": "repo_context_indexer_v2",
"items": [
{
"path": "tests/invoice-discount.test.ts",
"reason": "failing_test",
"priority": 1
},
{
"path": "src/billing/applyDiscount.ts",
"reason": "imported_by_failing_test",
"priority": 1
},
{
"path": "src/billing/couponRules.ts",
"reason": "called_by_applyDiscount",
"priority": 2
},
{
"path": "src/billing/memberPrice.ts",
"reason": "mentioned_in_old_summary_only",
"priority": 5
}
],
"excluded": [
{
"path": "README.md",
"reason": "contains stale test command; not relevant to failing assertion"
}
]
}注意这里没有完全禁止模型读其他文件。工程上不要把上下文做成死板的笼子。它应该提供默认路线,也允许模型在证据不足时申请扩展。关键是扩展要有理由,并被记录。
一次合理的文件读取日志可以长这样:
{
"event": "tool_call",
"trace_id": "fix-1842",
"step": "read_related_files",
"tool": "repo.read_files",
"input": {
"paths": [
"tests/invoice-discount.test.ts",
"src/billing/applyDiscount.ts",
"src/billing/couponRules.ts"
]
},
"policy": {
"allowed": true,
"reason": "paths selected from failing test imports"
},
"output_summary": {
"files_read": 3,
"total_chars": 12380,
"truncated": false
}
}这类日志不是为了好看。等 Agent 改错文件时,你能马上知道它为什么读了那个文件:是失败测试导入,还是旧摘要误导,还是模型自己扩展。
把“不能做什么”写成硬约束
代码修复 Agent 最常见的坏行为,不是不会修,而是用错误方式让 CI 变绿。删除测试、跳过断言、扩大条件、吞掉异常、改快照、降低类型检查,都是典型捷径。
这些约束不能只藏在系统提示词里一句“请保持代码质量”。它们应该进入上下文包,并且可被静态检查或 diff 检查验证。
{
"constraints": [
{
"id": "no_test_weakening",
"severity": "blocker",
"rule": "不得删除、跳过、放宽失败测试,除非用户明确要求更新业务预期",
"check": "diff_scan:test_assertion_changed"
},
{
"id": "minimal_behavior_change",
"severity": "blocker",
"rule": "修复范围限定在 WELCOME10 新用户折扣,不改变会员价、满减券和手工折扣",
"check": "targeted_test_matrix"
},
{
"id": "no_secret_output",
"severity": "blocker",
"rule": "日志、PR 描述和评论不得包含环境变量、token、私有 URL",
"check": "secret_redaction_scan"
}
]
}约束写到这个程度,模型就不再只是“被提醒”。系统可以在 Agent 生成 diff 后做自动检查:测试文件断言变了没有?折扣矩阵里其他券结果变了没有?PR 描述有没有疑似密钥?如果检查没过,Agent 不能直接创建 PR,而要回到修复步骤。
很多团队把安全和质量都压在 prompt 上,这是不够的。Prompt 负责表达意图,约束系统负责拦截坏动作。
一轮修复到底给模型看什么
当 Agent 进入“分析并提出补丁”这一步时,我希望模型看到的是一张干净工作台,而不是资料仓库。最终输入可以被渲染成自然语言,但背后必须来自结构化上下文。
模型这一轮需要看到:
目标:
修复 CI run ci-20260615-1842 中 tests/invoice-discount.test.ts 的失败,并创建 PR。
验收:
- npm test 通过
- 不删除、不跳过、不放宽失败测试
- 不改变 WELCOME10 之外的折扣语义
主要证据:
- npm test 失败:applyDiscount applies WELCOME10 for new customers
- 断言:expected 9900 to equal 9000
- 测试位置:tests/invoice-discount.test.ts:28
- 原始日志:artifact://ci-20260615-1842/log.txt#L810-L846
已读取文件:
- tests/invoice-discount.test.ts
- src/billing/applyDiscount.ts
- src/billing/couponRules.ts
当前观察:
- 测试期望 WELCOME10 对 new customer 产生 10% discount
- couponRules.ts 中 WELCOME10 的 rate 是 0.1
- applyDiscount.ts 在 coupon 存在时使用 subtotal - rate,而不是 subtotal * (1 - rate)
禁止动作:
- 不修改测试期望来适配 9900
- 不跳过该测试
- 不改会员价逻辑这里最有价值的不是文字本身,而是它的边界。每条观察都来自已读文件或 CI 证据,不混入模型猜测。旧对话里“会员价可能要调整”没有进入主要证据,因为它只来自历史摘要且与当前失败没有直接关系。
如果模型需要更多信息,比如想确认 rate 的单位,它可以申请读更多文件。申请也要结构化:
{
"request": "read_more_files",
"reason": "确认 coupon rate 在其他测试中的单位是否统一为小数比例",
"paths": ["tests/coupon-rules.test.ts"]
}这比让模型随手乱开文件要好得多。我们不是限制模型思考,而是要求它为扩展上下文付出一点解释成本。
补丁生成后,新的上下文来自 diff
Agent 生成补丁后,上下文不能还停留在“准备修复”。下一步的工作台应该围绕 diff 和验证结果重建。
假设补丁是:
- const discount = rule.rate
- return subtotal - discount
+ const discount = subtotal * rule.rate
+ return subtotal - discount上下文包增加一个 proposed_change:
{
"type": "proposed_change",
"files": ["src/billing/applyDiscount.ts"],
"diff_summary": [
"将 WELCOME10 等比例折扣从固定金额扣减改为按 subtotal * rate 扣减"
],
"risk": {
"touched_test_files": false,
"touched_public_api": false,
"possible_behavior_change": "所有使用 percentage rate 的 coupon 会受影响"
},
"required_validation": [
"npm test -- tests/invoice-discount.test.ts",
"npm test -- tests/coupon-rules.test.ts",
"npm test"
]
}这里出现了一个真实工程问题:补丁可能影响所有百分比券,而不只是 WELCOME10。模型如果只跑失败测试,风险没有被覆盖。上下文系统应该根据 diff 触发验证矩阵,而不是让模型自己凭感觉决定跑什么。
验证日志也要结构化:
{
"event": "validation_result",
"trace_id": "fix-1842",
"commands": [
{
"cmd": "npm test -- tests/invoice-discount.test.ts",
"exit_code": 0,
"duration_ms": 1840
},
{
"cmd": "npm test -- tests/coupon-rules.test.ts",
"exit_code": 0,
"duration_ms": 1260
},
{
"cmd": "npm test",
"exit_code": 0,
"duration_ms": 9340
}
],
"coverage_of_constraints": {
"no_test_weakening": "passed",
"minimal_behavior_change": "passed",
"no_secret_output": "passed"
}
}最终 PR 描述不应该靠模型自由发挥。它应该从目标、diff 摘要和验证结果里生成:
## Summary
- 修复百分比优惠券折扣计算,将 rate 按 subtotal 比例应用
- 保持失败测试预期不变,未修改测试文件
## Test Plan
- npm test -- tests/invoice-discount.test.ts
- npm test -- tests/coupon-rules.test.ts
- npm test这个 PR 描述很普通,但它可靠。它没有泄露 CI 原始日志,没有出现内部 URL,没有把模型猜测写成事实。
错误场景一:历史摘要污染当前任务
上下文工程必须处理错误,不然只是漂亮设计。第一个常见错误是历史摘要污染。
比如旧任务摘要里有一句:
{
"type": "conversation_summary",
"created_at": "2026-06-10T09:00:00Z",
"content": "用户之前怀疑会员价逻辑存在问题,可能需要调整 memberPrice.ts",
"confidence": 0.42
}旧版 Agent 会把这句话和 CI 失败并列放进 prompt。模型看到“会员价逻辑”几个字,就可能开始读 memberPrice.ts。改造后,这条摘要仍然可以保留,但必须被降权:
{
"admission": "background_only",
"reason": "not linked to current failing test stack or diff",
"conflicts_with": [],
"may_enter_model_context": false
}不是所有历史都值得进入模型上下文。历史可以进审计,可以进候选池,但不应自动进入当前工作台。尤其是低置信度猜测,必须防止被摘要器改写成事实。
错误场景二:工具输出压缩丢掉关键行
第二个错误来自压缩。CI 日志摘要器如果只保留最后一个失败,可能漏掉前面更关键的初始化错误。解决办法不是不压缩,而是让压缩有质量指标。
每次工具输出压缩后,记录这些字段:
{
"compression": {
"raw_chars": 184220,
"summary_chars": 2410,
"strategy": "failure-focused",
"dropped_sections": [
{"name": "dependency_install", "reason": "exit_code_0"},
{"name": "lint_warnings", "reason": "non_blocking"}
],
"must_keep_patterns": [
"FAIL ",
"Error:",
"AssertionError",
"exit code"
],
"quality_checks": {
"contains_exit_code": true,
"contains_stack_top": true,
"contains_failed_test_name": true
}
}
}如果 quality_checks.contains_failed_test_name 为 false,这份摘要不能进入主上下文,只能触发重新提取。这样做很琐碎,但比让模型读坏摘要强得多。
错误场景三:CI 本地复现不了
真实项目里,经常遇到 CI 失败但本地无法复现。旧版 Agent 往往会继续猜,猜到最后改出一个“可能有帮助”的补丁。上下文包应该把这种状态明确暴露出来:
{
"type": "reproduction_status",
"ci_failed": true,
"local_reproduction": {
"command": "npm test -- tests/invoice-discount.test.ts",
"exit_code": 0,
"environment_diff": [
"CI uses Node 22.2.0, local uses Node 20.11.1",
"CI has TZ=UTC, local TZ=Asia/Shanghai"
]
},
"next_allowed_actions": [
"align_node_version",
"run_with_ci_env",
"inspect_test_time_dependency"
],
"blocked_actions": [
"create_pr_without_reproduction_or_explanation"
]
}这类状态能阻止 Agent 装作问题已经理解。上下文系统要允许“不知道”,并把“不知道”变成可行动的下一步。生产 Agent 最大的风险之一,是在证据不足时仍然输出确定结论。
错误场景四:修复通过,但验证不完整
还有一种情况更隐蔽:失败测试通过了,全量测试没跑,Agent 就准备开 PR。很多模型会倾向于“完成任务”,尤其当用户说“帮我尽快修好”时。
所以验证不是模型自由选择,而是由上下文包里的 required_validation 驱动。创建 PR 前,系统检查:
{
"pr_gate": {
"required": [
"targeted_failing_test_passed",
"related_test_matrix_passed",
"full_test_command_passed",
"diff_policy_passed",
"secret_scan_passed"
],
"actual": {
"targeted_failing_test_passed": true,
"related_test_matrix_passed": true,
"full_test_command_passed": false,
"diff_policy_passed": true,
"secret_scan_passed": true
},
"decision": "blocked",
"reason": "full_test_command_missing"
}
}被拦住后,模型可以继续跑测试,或者向用户说明全量测试因环境缺失无法运行。它不能悄悄跳过。
让上下文可以回放
如果 Agent 出错后只能看到最终回答,工程团队基本没法修。可维护的 Agent 必须能回放每一步模型看到的上下文。
我会为每个任务保存五类记录。
一是 context_package,也就是每一步的输入包。二是 model_rendered_context,即结构化包渲染成模型消息后的实际文本。三是 tool_trace,记录工具调用、参数摘要、输出摘要、耗时、策略判断。四是 diff_trace,记录模型提议的补丁、实际应用的补丁、自动检查结果。五是 decision_trace,记录模型为什么选择下一步。
一次简化 trace 可以是:
{
"trace_id": "fix-1842",
"context_version": "code_fix_context_v1",
"model": "example-code-model",
"steps": [
{
"name": "collect_ci_failure",
"input_refs": ["ci-20260615-1842"],
"output_refs": ["evidence:ci_failure:01"]
},
{
"name": "select_files",
"input_refs": ["evidence:ci_failure:01"],
"output_refs": ["evidence:file_candidates:01"]
},
{
"name": "propose_patch",
"model_context_hash": "sha256:7b1...",
"output_refs": ["diff:patch:01"]
},
{
"name": "validate",
"output_refs": ["validation:01"]
},
{
"name": "create_pr",
"gate": "passed"
}
]
}有了回放,问题会从“模型怎么又幻觉了”变成具体工程项:CI 摘要器漏了关键行,文件候选器把旧摘要权重设高了,diff gate 没检查测试断言,PR 模板把未验证命令写进去了。能定位,就能修。
上下文预算不是总 token 限制
长上下文窗口会诱惑人偷懒。能塞几十万 token,不代表应该塞。代码修复任务里,我会给不同材料分预算:
| 区域 | 初始预算 | 说明 |
|---|---|---|
| 当前目标与硬约束 | 10% | 必须完整保留,不参与普通裁剪 |
| CI 失败证据 | 15% | 保留失败摘要、关键堆栈、原文引用 |
| 相关测试与实现代码 | 40% | 优先当前失败链路 |
| 最近 diff | 15% | 只放与失败文件相关的 diff |
| 项目约定 | 10% | 测试命令、代码风格、PR 要求 |
| 历史摘要 | 5% | 只放已验证且仍适用的偏好 |
| 工具说明 | 5% | 只放本轮可用工具的 schema 摘要 |
预算不是死数。CI 日志很短时,把空间让给代码;相关代码太长时,先保留函数签名、调用点、失败行附近,再允许模型按需读取;历史摘要除非直接影响当前约束,否则不该挤掉证据。
裁剪也要记录:
{
"trim_log": [
{
"source": "README.md",
"chars": 6200,
"decision": "excluded",
"reason": "stale command and no relation to failing assertion"
},
{
"source": "src/billing/memberPrice.ts",
"chars": 3100,
"decision": "excluded_from_model_context",
"reason": "only linked by low-confidence old summary"
}
]
}没有裁剪日志,排查上下文问题会非常痛苦。你不知道模型没看到某条信息,是因为检索不到、预算不够、被判断无关,还是中间代码写漏了。
评估要看上下文包,而不只看最终答案
很多团队评估 Agent,只看“任务有没有完成”。这太晚了。上下文质量本身就应该有指标。
对于这个代码修复 Agent,我会跟踪这些指标:
| 指标 | 含义 | 坏信号 |
|---|---|---|
primary_failure_capture_rate | 是否正确捕获主失败 | Agent 总在无关 warning 上浪费时间 |
relevant_file_hit_rate | 候选文件是否覆盖真实修复文件 | 模型频繁盲目搜索 |
stale_context_ratio | 进入模型的过期材料比例 | 旧 README、旧摘要影响判断 |
constraint_gate_block_rate | 约束 gate 拦截次数 | 模型常尝试改测试或跳验证 |
reproduction_success_rate | 本地复现成功率 | 环境上下文不足 |
pr_reopen_rate | PR 因修复不完整被打回比例 | 验证矩阵不够 |
这些指标不需要一次全部自动化。先从十几个真实失败样本做回放集就够。每次改 CI 摘要、文件检索、上下文模板或模型版本,都重新生成 context package,比对它是否更干净。
最终答案一样,不代表系统一样好。一个 Agent 可能这次侥幸修对了,但依据的是错误文件和模型猜测;另一个 Agent 可能补丁相同,但证据链清楚、验证完整。上线后我更信后者。
实施清单:从一个失败测试开始
如果你已经有一个能跑的代码 Agent,不需要推倒重来。可以按这个顺序改。
先把“最终发给模型的内容”完整保存下来。不要急着优化,只要给每段内容加来源标签:用户输入、CI、文件、历史、工具说明、模型摘要。很多问题在这一步就会暴露,比如旧摘要占了三分之一上下文,真正失败日志只有两行。
然后把 CI 输出改成结构化证据。保留失败测试名、断言、堆栈顶、命令、exit code、原文引用、非阻塞噪声。不要让完整日志直接进入模型。
再做文件候选器。最简单可以从失败测试 import、堆栈路径、git diff --name-only 和代码搜索开始。候选器不必完美,但要记录每个文件为什么被选中。
接着加硬约束和 gate。不要修改测试来过 CI,不要跳过测试,不要输出 secret,不要在验证不完整时创建 PR。这些规则要能检查,不能只写给模型看。
最后做回放集。挑二十个历史 CI 失败任务,包括修错过的、复现不了的、环境问题、测试本身有问题的。固定输入,保存 context package。以后每次改上下文模板,先跑这二十个样本。
一条链路跑通后,再扩展到更多任务类型。上下文工程最怕一上来平台化,最后变成一堆抽象配置。先让一个真实场景变得可解释、可验证、可回滚。
什么时候不要继续自动修
还有一个不讨喜但很重要的设计:Agent 要知道什么时候停。
这些情况我会让它停止自动修改,转为询问或提交诊断报告:CI 失败无法本地复现且环境差异不明;失败测试本身和产品需求冲突;修复需要改公开 API;涉及数据迁移;验证命令持续不稳定;补丁需要删除大量代码;上下文里出现高置信度冲突证据。
停止不是失败。对生产 Agent 来说,错误地继续比诚实地停下更糟。上下文包应该给模型提供“停”的合法路径,而不是把所有任务都包装成必须完成的命令。
比如 PR gate 可以返回:
{
"decision": "needs_user_confirmation",
"reason": "test expectation conflicts with current product spec document",
"safe_next_message": "我找到了一个冲突:测试要求 WELCOME10 给新用户 10% 折扣,但当前产品说明写的是首单固定减 100。需要确认以哪一个为准。"
}这比模型擅自选一个方向改代码强得多。
最后,Context Engineering 是团队接口
很多人把上下文工程理解成模型调用前的一段拼接逻辑,我觉得太窄了。它其实是团队之间的接口。
平台团队负责 context package、trace、gate、版本和回放。业务工程师负责提供真实失败样本、领域约束和验收矩阵。安全团队负责 secret 扫描、权限边界和日志保留。产品或研发负责人负责定义哪些动作可以自动完成,哪些必须确认。
如果这些责任不清,Agent 做错时就会互相甩锅。模型团队说业务上下文不足,业务团队说模型不靠谱,平台团队说 prompt 已经写了,安全团队说日志不够。Context package 的价值,是把争论落到具体字段上。
我判断一个代码 Agent 是否进入可维护阶段,会看四个问题:它看到的最高优先级目标是什么?它依据了哪些证据?哪些材料被裁掉,为什么?它创建 PR 前通过了哪些 gate?
这四个问题答不上来,就还停在 prompt 拼接阶段。答得上来,才有资格继续谈模型选择、成本优化和更复杂的自动化。
Prompt 可以让 Agent 看起来像个资深工程师。Context Engineering 才能让它在真实项目里少把旧笔记当需求、少把 warning 当根因、少把改测试当修 bug。生产系统最后拼的不是一句神奇提示词,而是每一次行动前,那张被整理过、能回放、能质疑的工作台。