
Gemma 4 12B 实战:本地代码生成、OpenClaw 和 QVeris 工具调用
古董级程序员,大厂出来后一直在创业公司,现在还在一线写 AI 相关的后端。更完整的技术记录写在微信公众号「字与码」:踩过的坑、换技术栈时的权衡、和这些年绕过的弯路,会不定期发在那里。若这篇对你有用,欢迎顺手关注。
最近在本地测试机上把 gemma4:12b 跑起来了。模型通过 Ollama 下载和服务,前面先做了一个很小但很能说明问题的实验:让它生成 HTML Canvas 分形树。后面又把它接入 OpenClaw,通过 QVeris 去调真实 API,看它能不能在 agent 工作流里完成“拿数据、读结果、做判断”的任务。
先说结论:Gemma 4 12B 可以放进 OpenClaw 和 QVeris 的候选模型里,但不能直接当成免调试的默认答案。 它能写代码,能读结构化工具结果,也有不错的本地输出速度;但 prompt 要写清楚,工具结果也要校验。把它当成一个本地可部署、能被 Codex 辅助编排的执行模型,会比把它当成“全自动高级工程师”更合理。
为什么看 Gemma 4 12B
Google 在 2026 年 6 月发布 Gemma 4 12B,官方定位很明确:这是一个可以在本地和日常开发机上跑的开放权重模型,重点打的是 multimodal、agentic reasoning、coding 和本地工作流。Google 的介绍里提到,它面向普通 16GB 级别机器,本地运行时内存占用远低于更大的 26B MoE;开发者指南也直接点名可以接到 Continue、Aider、OpenClaw、Hermes、OpenCode 这类工具链里。
我关心的不是它在排行榜上能不能打赢大模型,而是它能不能成为一个“本地可用的工具型模型”。
Ollama 侧也已经提供了 gemma4:12b 入口。Ollama 模型页把 Gemma 4 描述为 Google DeepMind 的开放模型,支持文本和图像输入,强调 reasoning、coding、agentic capability、native function calling、system role,以及更长上下文。对我们这种已经有 OpenClaw、QVeris、Codex 和本地服务编排的人来说,这些关键词比单纯聊天能力更重要。
这篇文章主要用两组实践来评估:
| 实验 | 看什么 |
|---|---|
| 分形树 HTML Canvas 代码生成 | prompt 质量对代码结果的影响、模型能否产生可运行前端代码 |
| OpenClaw + QVeris 数据调用 | 模型能否读取真实工具结果、识别错工具、给出结构化评价 |
下面的判断都落到这两组实测上。
官方能力和我真正关心的能力
官方文档里最值得注意的是三点。
第一,Gemma 4 12B 是本地模型,但不是“只能聊天的小模型”。Google Developers Blog 列出的能力包括自动语音识别、agentic reasoning、说话人分离、视频理解、coding 等。也就是说,它不是只面向普通问答,而是明确往 agent 和多模态工作流走。
第二,Google 明确把它放进本地 agent 工具链场景里。开发者指南里提到,可以通过本地 OpenAI-compatible API server 接入 Continue、Aider、OpenClaw、Hermes、OpenCode 等工具。这个说法对我很关键,因为 OpenClaw 和 QVeris 本来就是工具调用场景,不是一个普通聊天窗口。
第三,Gemma 4 12B 的设计目标不是最大模型的绝对能力,而是在本地资源和能力之间取平衡。Google 官方介绍说它在标准 benchmark 上接近更大的 26B MoE,但内存占用不到一半,并强调它可以在 16GB RAM 的消费级设备上本地运行。Ollama 页面也给了不同量化与模型标签,对本地部署比较友好。
这些资料给了我一个预期:它应该能做一部分代码生成和工具结果解释,但不应该期待它在模糊需求、长链路规划和工具选择上完全替代更强模型。
实验环境和模型调用速度
这次模型在本地测试机上通过 Ollama 运行,调用模型名是 gemma4:12b。后面的 OpenClaw 评测里也把默认模型指向 ollama/gemma4:12b。
本地测试机配置如下:
| 配置项 | 规格 |
|---|---|
| CPU | Intel Core i9-14900KF |
| 内存 | 32GB |
| GPU | NVIDIA RTX 4090 24GB |
| 系统 | Ubuntu 26.04 LTS |
| 磁盘 | 4TB SSD |
用户给出的第三次分形树结果里,Ollama usage 是:
{
"total_duration": 71056910081,
"load_duration": 256789653,
"prompt_eval_count": 370,
"prompt_eval_duration": 98918000,
"eval_count": 5864,
"eval_duration": 70579437000
}换算成人能读的指标:
| 指标 | 数值 |
|---|---|
| 总耗时 | 71.06 秒 |
| 模型加载耗时 | 0.26 秒 |
| prompt tokens | 370 |
| prompt 处理耗时 | 0.099 秒 |
| prompt 处理速度 | 约 3740 tokens/s |
| 输出 tokens | 5864 |
| 输出耗时 | 70.58 秒 |
| 输出速度 | 约 83.08 tokens/s |
| 端到端输出速度 | 约 82.53 tokens/s |
这个结果说明两件事。
第一,慢不在 prompt 处理,也不在模型加载。第三版 prompt 很长,但只有 370 个 prompt tokens,prompt eval 不到 0.1 秒。真正耗时的是输出:模型生成了 5864 个 tokens,用掉 70 秒多。
第二,83 tokens/s 对本地 12B 模型来说是可以接受的,尤其是写一份完整 HTML 时。问题不在速度,而在“输出这么长,最后效果是否值得”。第三版正好给了一个反例:prompt 最严格、输出最长、动画最符合要求,但树的视觉效果反而不如第一版。
这也是我对 Gemma 4 12B 的第一条判断:它的本地速度足够让人愿意试错,但试错质量取决于你怎么组织任务。
分形树实验:同一个任务,三种 prompt,三种结果
分形树实验的目标很简单:让模型生成一个单文件 HTML5 Canvas 页面,画一棵递归分形树,而且要有从底部向上生长的动画。
先说明一下,下面三张图都只是静态截图。真正测试时看的是 HTML 页面里的生长动画和风吹摆动效果,截图只能展示最终树形,不能完整反映动画节奏。
这个任务表面是“小前端”,实际对模型有几个要求:
- 知道 Canvas 2D 绘制;
- 能写递归分支算法;
- 能把全局生长进度分配到不同递归层级;
- 能避免一开始就画完整树;
- 能用
requestAnimationFrame做动画; - 还能把风吹摆动和生长动画区分开。
这不是特别难的工程任务,但很适合看 12B 模型的代码生成边界。
第一版:原始结果有 bug,修好后效果最好
第一版 prompt 是从零开始生成页面:
Create an HTML page featuring a fractal tree growing upwards using Canvas and a recursive algorithm. Feature 1: Growing animation (growth process). Feature 2: Swaying/swaying movement (wind effect). Requirement: clean HTML code (no extra escape characters), usable directly.一开始生成的结果有问题,不能直接达到预期。后来让 Codex 介入修复,修好以后运行效果反而是三版里最好的。

第一版的树形有几个优点:主干稳定,树冠展开自然,枝条密度高但没有糊成一团,整体像一棵经过抽象的伞状树。它不一定是最严格遵守“动画阶段”的版本,但作为最终视觉结果,它最好看。
这说明一个很重要的问题:模型生成代码时,第一次从零生成不一定能直接交付,但它给出的主体结构可以继续修。 第一版就是这样:Gemma 4 12B 先生成主体,Codex 再把不能直接运行或不符合预期的地方补上。
在这个组合里,Gemma 4 12B 负责生成主体代码,Codex 负责检查可运行性和修补细节。这个工作流比“让本地 12B 模型独立交付完整前端作品”可靠得多。
第二版:重新写 prompt 后,离成功很近
第二版是让 Codex 重新组织 prompt,再让 Gemma 4 12B 从零生成完整页面。核心要求包括:
Create a complete single-file HTML5 Canvas page.
Return only clean runnable HTML code, no Markdown.
Use a recursive fractal tree algorithm.
The tree must visibly grow upward from an empty canvas: trunk first, then large branches, then smaller branches and leaves.
Use a global growthProgress value from 0 to 1.
Each branch must compute its own growth phase from recursion level and draw only a partial segment while growing.
Add subtle wind sway by oscillating branch angles over time.
Do not draw the full tree immediately.
Make the canvas responsive.
Use normal HTML quotes, not escaped quotes.这个 prompt 比第一版更清楚,尤其是明确了“每个 branch 要有自己的 growth phase”。结果确实更接近成功。

第二版的问题是动画帧率太高,或者说生长节奏太快。视觉上它已经有递归树结构,细枝也比较自然,但“从空白到生长完成”的过程不够可控。这个问题不是代码完全错,而是动画时间模型不够明确。
这给我的启发是:对这类本地模型,prompt 不能只写“smooth animation”“visibly grow”,还要写清楚时间计算方式。否则模型会用简单的帧增量,例如 progress += 0.01,在不同机器和帧率下表现不稳定。
第三版:prompt 最复杂,动画正常了,树变差了
第三版 prompt 进一步强化了动画要求:
The full growth animation must take about 10 seconds.
Do not use frame-based increments like progress += 0.01.
Use requestAnimationFrame timestamp and compute growthProgress from elapsed time:
growthProgress = Math.min(1, (timestamp - startTime) / 10000)
Use an easing function such as easeInOutCubic so the growth is smooth and not too fast.
The trunk should grow first, then large branches, then smaller branches and leaves.
Each recursive branch must have its own growth window based on its recursion level.
A solution is invalid if the full tree appears within the first 5 seconds.这次动画正常了,但树的效果变差了。

第三版主干粗,枝条形态更机械,树冠像一层绿色边框,少了第一版那种自然展开的感觉。它更像“严格执行动画规范的示例代码”,而不是“好看的分形树”。
这就是小模型代码生成里很常见的现象:prompt 越复杂,模型越容易把精力放在满足显式约束上,牺牲那些没有被精确定义的审美和结构平衡。
所以,我不会把第三版看成失败。它证明了模型能听懂“用 timestamp,不要按帧增量”“10 秒增长”“5 秒内不能完整出现”这些工程约束。但它也提醒我们:如果任务同时有行为约束和视觉质量要求,prompt 需要把两者都讲清楚,或者把任务拆成两步。
更好的流程应该是:
- 先生成可运行、视觉形态好的树;
- 再要求 Codex 或模型局部修改动画 timing;
- 不要一次性把所有约束都压进一个 prompt。
从分形树看 Gemma 4 12B 的代码能力
三版分形树给出的判断,比跑一个 benchmark 更具体。
| 版本 | 输入方式 | 结果 | 结论 |
|---|---|---|---|
| 第一版 | 从零生成短 prompt | 初始有问题,Codex 修复后效果最好 | 短 prompt 能给出好形态,但需要外部检查和修复 |
| 第二版 | Codex 重新生成 prompt | 接近成功,但动画太快 | 好 prompt 能显著提高结果质量 |
| 第三版 | 更严格的动画 prompt | 动画正常,树形变差 | 约束越多,模型越可能牺牲隐性质量 |
我的评价是:Gemma 4 12B 可以做代码生成,但更适合“有明确边界的局部任务”,不适合“模糊审美 + 多约束 + 一次性交付”。
如果要把它放进实际工程工作流,最好配合:
- Codex 做 prompt 整理和结果修复;
- 浏览器截图或测试脚本做可运行验证;
- 小步迭代,不要一次要求完整产品;
- 对输出格式写清楚,例如“只返回完整 HTML,不要 Markdown”;
- 对动画、时间、状态机这类动态行为给出明确公式。
这比单纯说“12B 模型会不会写代码”更有意义。
接入 OpenClaw + QVeris:这才是我更关心的部分
代码生成只是第一步。我真正想验证的是:Gemma 4 12B 能不能放进 OpenClaw,和 QVeris 一起组成一个本地工具调用链。
这次完整测试是用 Codex 完成的。流程大致是:
- OpenClaw 默认模型指向
ollama/gemma4:12b; - 每个案例先用 qveris-official 脚本执行
discover; - Codex 根据 discover 返回的候选工具、参数描述和目标构造参数;
- QVeris call 成功后记录 tool_id、参数、耗时、credits、执行结果;
- 把 QVeris 核心结果摘要交给本地
gemma4:12b; - 要求模型输出结构化 JSON 评分;
- Codex 汇总原始记录、评分和速度指标。
这里有一个现实插曲:OpenClaw agent CLI 在评测 prompt 上触发了 CLI transcript compaction failed: Already compacted,所以最终 token/速度探针改走本地 Ollama API。模型本身仍然是 OpenClaw 已接入的同一个 gemma4:12b。
这和“实际通过 OpenClaw 调用大模型”有区别。OpenClaw 路径会带上 agent 的系统提示、workspace bootstrap、工具说明、会话历史、compaction 逻辑和工具调用循环;Ollama API 路径只是在同一台机器上直接调用同一个模型,对固定输入做一次推理。因此,Ollama API 的 token 和速度数据只能说明 gemma4:12b 这个模型本身的吞吐和结构化评价能力,不能代表 OpenClaw 端到端耗时,也不能覆盖 OpenClaw 的上下文压缩、工具协议和失败恢复成本。
这次评测里,QVeris 的 discover/call 链路仍然是真实执行的;改走 Ollama API 的只是“把工具结果交给模型评价”这个探针。换句话说,数据调用能力看的是 OpenClaw/QVeris 组合能不能接起来,速度探针看的是同一个本地模型在脱离 OpenClaw CLI 后的基础表现。两者要分开看。
QVeris 测试方法
这次 QVeris 测试覆盖 10 个案例,包含金融、天气、空气质量、股票和学术检索。
评测规则是:
- 数据正确性:结果是否命中目标实体、市场、城市、币种、符号或论文主题;
- 推理质量:模型是否能识别业务字段、异常状态、工具错配、单位/报价方向;
- 指令遵循:模型是否按要求输出结构化 JSON;
- QVeris 有用性:工具结果对最终回答是否直接有用;
- 每项 1 到 5 分,5 表示直接可用,3 表示部分可用但需人工校验,1 表示错工具或结果不可用。
模型调用参数固定为:
temperature=0.1num_ctx=40960stream=false
速度口径:
prompt_eval_count作为输入 tokens;eval_count作为输出 tokens;- 输出速度 =
eval_count / eval_duration; - prompt 处理速度 =
prompt_eval_count / prompt_eval_duration。
QVeris credits 口径也很明确:报告里的 credits 消耗以 call 结果的 cost 字段为准,不用 expected_cost 代替实际消耗。
总览结果
这次完整成功案例是 10/10,也就是每个案例都完成了 QVeris 工具调用和本地模型评估。
| 指标 | 结果 |
|---|---|
| 完整成功案例 | 10/10 |
| QVeris 总 credits 消耗 | 37.02 |
| QVeris 平均 call 耗时 | 879.81 ms |
| Gemma 4 12B 平均端到端耗时 | 24957.10 ms |
| Gemma 4 12B 平均输出速度 | 83.75 tokens/s |
| Gemma 4 12B 平均 prompt 处理速度 | 4947.62 tokens/s |
| 平均数据正确性评分 | 4.30/5 |
| 平均推理评分 | 4.50/5 |
| 平均指令遵循评分 | 4.40/5 |
| 平均 QVeris 有用性评分 | 4.20/5 |
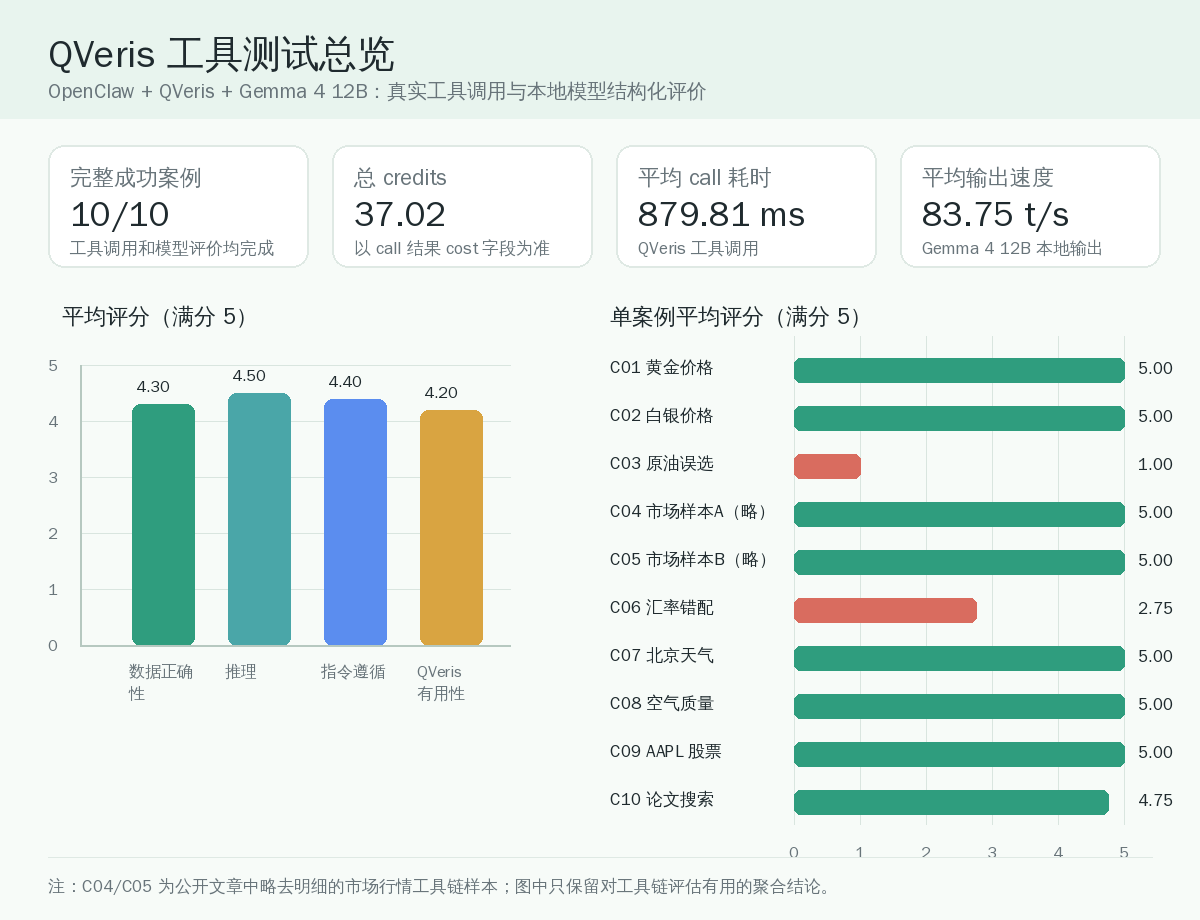
这张图把 QVeris call、credits、Gemma 4 12B 输出速度和单案例评分放在一起看。最直观的结论是:多数案例的模型评价很稳定,真正拉低均分的是 C03 的工具误选和 C06 的参数错配。这两个问题都不是“模型不会读 JSON”,而是 agent 编排层需要更强的工具选择和业务字段校验。
从这个总览看,Gemma 4 12B 最适合的位置是“工具结果解释器”和“结构化评估器”。它读取 JSON 结果、判断是否命中目标、发现明显工具错配,这些能力基本够用。
但它不能单独解决所有问题,因为最容易出错的地方在工具选择和参数构造。这个环节目前还是 Codex 在兜底:它把自然语言目标转成 capability query,解析 QVeris 工具参数,失败后换候选工具。
换句话说,OpenClaw + QVeris + Gemma 4 12B 是可用组合,但最好再加一个更强的编排层,至少在早期阶段由 Codex 帮忙做工具选择和校验。
10 个 QVeris 案例完整记录
下面把飞书评测报告里的 10 个案例完整整理进来。为了适合公开文章,我去掉了本地文件目录、余额和带签名的临时下载 URL,但保留目标、discover query、tool、参数、耗时、credits、模型 usage、评分、结论和关键结果摘录。
C01:黄金现货价格
- 目标:Get the latest gold XAU rate quoted in USD.
- Discover 查询:
commodity price API - 选中工具:
commodity_price_api.rates.latest.retrieve.v2.5d72a6b6 - 工具成功率窗口:90%,样本数 41
- 调用参数:
{"symbols":"xau","quote":"usd"} - QVeris call 耗时:715.59 ms
- QVeris credits 消耗:9.55
- 模型 wall time:15727 ms
- 模型 usage:input 525 tokens,output 1001 tokens,total 1526 tokens
- 模型速度:输出 85.06 tokens/s,prompt 3676.83 tokens/s
- 评分:数据正确性 5/5,推理 5/5,指令遵循 5/5,QVeris 有用性 5/5
- 模型结论:QVeris 成功返回 XAU/USD 价格,
rates.XAU = 4312.51,metadata 明确 unit 为 troy ounce、quote 为 USD。 - 风险备注:无。
结果摘录:
{
"status_code": 200,
"data": {
"success": true,
"timestamp": 1780890505,
"rates": {
"XAU": 4312.51
},
"metadata": {
"XAU": {
"unit": "T.oz",
"quote": "USD"
}
}
}
}C02:白银价格
- 目标:Get the latest silver XAG rate quoted in USD.
- Discover 查询:
commodity price API - 选中工具:
commodity_price_api.rates.latest.retrieve.v2.5d72a6b6 - 工具成功率窗口:90%,样本数 41
- 调用参数:
{"symbols":"xag","quote":"usd"} - QVeris call 耗时:740.43 ms
- QVeris credits 消耗:9.55
- 模型 wall time:13873 ms
- 模型 usage:input 522 tokens,output 1128 tokens,total 1650 tokens
- 模型速度:输出 84.80 tokens/s,prompt 4424.89 tokens/s
- 评分:数据正确性 5/5,推理 5/5,指令遵循 5/5,QVeris 有用性 5/5
- 模型结论:结果明确包含
rates.XAG = 67.64,对应白银 USD 报价。 - 风险备注:无,符号 XAG 识别明确。
结果摘录:
{
"status_code": 200,
"data": {
"success": true,
"timestamp": 1780890523,
"rates": {
"XAG": 67.64
},
"metadata": {
"XAG": {
"unit": "T.oz",
"quote": "USD"
}
}
}
}C03:原油基准价格,工具误选
- 目标:Get the latest crude oil benchmark price, preferably WTI or Brent.
- Discover 查询:
commodity benchmark price API - 选中工具:
commodity_price_api.usage.retrieve.v2.ef3bfeb2 - 工具成功率窗口:100.0%
- 调用参数:
{} - QVeris call 耗时:689.70 ms
- QVeris credits 消耗:9.55
- 模型 wall time:31319 ms
- 模型 usage:input 445 tokens,output 2584 tokens,total 3029 tokens
- 模型速度:输出 84.05 tokens/s,prompt 4690.68 tokens/s
- 评分:数据正确性 1/5,推理 1/5,指令遵循 1/5,QVeris 有用性 1/5
- 模型结论:工具返回的是账户 usage 信息,不是原油价格,完全不匹配用户需求。
- 风险备注:如果模型只看数字,可能把
quota=10000或used=128幻觉成油价。
结果摘录:
{
"status_code": 200,
"data": {
"plan": "plus",
"quota": 10000,
"used": 128
}
}这是一个很重要的失败样本。HTTP 200 不等于业务成功,工具成功率高也不等于这次选对了工具。Gemma 4 12B 在报告里能指出“不相关”,这说明它能做结果校验;但如果 agent 编排层没有让它校验目标和返回实体,错误数据还是可能进入最终回答。
C04 / C05:两个市场行情工具链样本(略)
原始评测里 C04 和 C05 是两个市场行情工具链样本,主要用于确认 QVeris discovery、call、结果解析和本地模型结构化评价能否跑通。
保留对评测结论有用的部分即可:这两个样本的 QVeris call 都成功,单次实际消耗均为 1.00 credits;Gemma 4 12B 能读取列表型 JSON,知道不能机械取第一项,而要根据目标实体在数组里找对应结果。这个观察对别的列表型 API 同样有用,比如论文搜索、股票列表、供应商搜索结果等。
C06:USD/CNY 汇率,参数错配
- 目标:Get the latest USD to CNY exchange rate.
- Discover 查询:
foreign exchange rate API - 选中工具:
twelvedata.exchangerate.retrieve.v1.9eeb3b0d - 工具成功率窗口:97.8%,样本数 135
- 调用参数:
{"symbol":"EUR/USD"} - QVeris call 耗时:455.41 ms
- QVeris credits 消耗:2.37
- 模型 wall time:48032 ms
- 模型 usage:input 470 tokens,output 3908 tokens,total 4378 tokens
- 模型速度:输出 82.44 tokens/s,prompt 5094.63 tokens/s
- 评分:数据正确性 2/5,推理 4/5,指令遵循 3/5,QVeris 有用性 2/5
- 模型结论:工具返回的是
EUR/USD,不是请求的USD/CNY。一个合格模型必须识别 pair 不一致,不能直接拿rate = 1.153回答 USD/CNY。 - 风险备注:高风险。模型可能忽略
symbol字段,把数值当正确答案。
结果摘录:
{
"status_code": 200,
"data": {
"symbol": "EUR/USD",
"rate": 1.153,
"timestamp": 1780890540
}
}这个案例非常有价值,因为它不是工具完全不可用,而是参数构造错了。模型本身能指出错配,但系统必须把“返回 symbol 是否等于目标 symbol”做成硬校验,不能只靠模型自觉。
C07:北京天气
- 目标:Get current or forecast weather for Beijing, China.
- Discover 查询:
weather forecast API - 选中工具:
visualcrossing.timeline.retrieve.v1 - 工具成功率窗口:100.0%,样本数 7
- 调用参数:
{"location":"Beijing, China"} - QVeris call 耗时:3144.84 ms
- QVeris credits 消耗:1.00
- 模型 wall time:15353 ms
- 模型 usage:input 1285 tokens,output 1222 tokens,total 2507 tokens
- 模型速度:输出 83.39 tokens/s,prompt 5873.18 tokens/s
- 评分:数据正确性 5/5,推理 5/5,指令遵循 5/5,QVeris 有用性 5/5
- 模型结论:工具返回北京天气数据,包括
Rain, Partially cloudy、温度范围和 forecast 描述。即使结果因长度被截断,关键字段仍足够回答。 - 风险备注:无。长结果需要截断策略,但摘要字段可用。
结果摘录:
{
"status_code": 200,
"message": "Result content is too long; truncated content is available.",
"truncated_content": {
"queryCost": 1,
"latitude": 39.9066,
"longitude": 116.388,
"resolvedAddress": "中国北京",
"address": "Beijing, China",
"timezone": "Asia/Shanghai",
"description": "Similar temperatures continuing with a chance of rain tomorrow, Sunday & Monday."
}
}C08:北京空气质量
- 目标:Get air quality data for Beijing, China.
- Discover 查询:
air quality API - 选中工具:
openweathermap.air_pollution.current.v2_5 - 工具成功率窗口:100.0%,样本数 8
- 调用参数:
{"lat":39.9042,"lon":116.4074} - QVeris call 耗时:259.95 ms
- QVeris credits 消耗:1.00
- 模型 wall time:26533 ms
- 模型 usage:input 629 tokens,output 2181 tokens,total 2810 tokens
- 模型速度:输出 84.21 tokens/s,prompt 4947.85 tokens/s
- 评分:数据正确性 5/5,推理 5/5,指令遵循 5/5,QVeris 有用性 5/5
- 模型结论:工具返回结构化空气质量数据,包括 AQI 和 PM2.5、NO2、O3 等污染物浓度。
- 风险备注:无。
结果摘录:
{
"status_code": 200,
"data": {
"coord": {
"lon": 116.4074,
"lat": 39.9042
},
"list": [
{
"main": {
"aqi": 4
},
"components": {
"co": 236.69,
"no": 2.54,
"no2": 11.53,
"o3": 128.04,
"so2": 33.06,
"pm2_5": 50.25,
"pm10": 60.94,
"nh3": 9.47
},
"dt": 1780890723
}
]
}
}C09:AAPL 实时股票行情
原来的 C09 是埃菲尔铁塔地理编码案例,discover 选到了高德地图 regeo 工具。这个工具不适合国外地点,而且语义上是“坐标反查信息”,不适合作为国外地理编码评测。后来按要求整体替换为股票实时行情查询,并且必须通过 QVeris 执行。
- 目标:Get the latest Apple Inc. AAPL stock quote in USD.
- Discover 查询:
stock quote real-time API - 选中工具:
finnhub_io_api.stock.quote - 工具成功率窗口:93.8%,样本数 3993
- 调用参数:
{"symbol":"AAPL"} - QVeris call 耗时:358.05 ms
- QVeris credits 消耗:1.00
- 模型 wall time:21729 ms
- 模型 usage:input 527 tokens,output 1591 tokens,total 2118 tokens
- 模型速度:输出 85.32 tokens/s,prompt 3896.20 tokens/s
- 评分:数据正确性 5/5,推理 5/5,指令遵循 5/5,QVeris 有用性 5/5
- 模型结论:工具成功返回 AAPL 实时 quote,包含 current price、high、low、open、previous close 等字段。
- 风险备注:无。
结果摘录:
{
"status_code": 200,
"data": {
"c": 307.34,
"d": -3.89,
"dp": -1.2499,
"h": 315.17,
"l": 307.15,
"o": 312.86,
"pc": 311.23,
"t": 1780689600
}
}这个案例说明 QVeris 对高频金融 API 场景是有价值的。股票 quote 工具成功率样本数也足够大,比一些低样本工具更值得缓存和复用。
C10:LLM agents 学术论文搜索
- 目标:Find recent academic papers about LLM agents or multi-agent LLM systems.
- Discover 查询:
academic paper search API - 选中工具:
semantic_scholar.paper.search.bulk.execute.v1.239dfd66 - 工具成功率窗口:50.0%,样本数 4
- 调用参数:
{"query":"LLM agents multi-agent large language models"} - QVeris call 耗时:1606.99 ms
- QVeris credits 消耗:1.00
- 模型 wall time:28976 ms
- 模型 usage:input 1234 tokens,output 2328 tokens,total 3562 tokens
- 模型速度:输出 82.34 tokens/s,prompt 5737.61 tokens/s
- 评分:数据正确性 5/5,推理 5/5,指令遵循 5/5,QVeris 有用性 4/5
- 模型结论:工具返回了与 LLM agents 和 multi-agent systems 相关的论文,包含具体标题;虽然结果过长被截断,但可见片段足够用于回答。
- 风险备注:长结果被截断,完整数据需要后续下载或分页处理。
结果摘录:
{
"status_code": 200,
"message": "Result content is too long; truncated content is available.",
"truncated_content": {
"total": 6523,
"data": [
{
"paperId": "0002dfcbf6a4c5d90ea9d114965f3a6d48946de6",
"title": "LLMs for Integrated Business Intelligence: A Big Data-Driven Framework Integrating Marketing Optimization, Financial Performance, and Audit Quality"
}
]
}
}从 QVeris 案例看模型可用性
这 10 个案例里,最重要的不是 10/10 都跑通,而是它暴露了三种不同层次的问题。
第一种是数据直接可用。黄金、白银、AAPL、空气质量都属于这类。工具返回结构清楚,模型能识别字段,最终回答风险低。
第二种是工具可用但需要解析。前面略去的列表型行情样本就是这样:工具返回的是一个数组,模型必须按目标实体定位结果,不能简单抽第一项。Gemma 4 12B 能指出这个要求,说明它不是简单抽第一个数字。
第三种是工具或参数错配。C03 原油返回 usage 信息,C06 USD/CNY 返回 EUR/USD。这里模型能识别问题,但这不能只靠模型。系统层必须做 entity、symbol、market、currency pair 校验。
所以,我对 OpenClaw + QVeris + Gemma 4 12B 的判断是:
| 环节 | 可用性 | 备注 |
|---|---|---|
| 读取结构化 JSON | 高 | 大部分案例能抓住关键字段 |
| 按要求输出评分 JSON | 较高 | 平均指令遵循 4.40/5 |
| 发现工具结果不匹配 | 中高 | 能识别 C03/C06,但最好做系统硬校验 |
| 自主选择工具 | 中 | 当前主要靠 Codex 编排 |
| 长结果处理 | 中 | 天气/论文搜索会截断,需要摘要或分页策略 |
| 实时金融数据回答 | 高 | 股票、商品等场景很适合工具增强 |
这就是我说它“可用但需要好的输入”的原因。Gemma 4 12B 不是不能做 agent,它的问题在于:agent 系统必须把任务边界、工具候选、参数校验和结果约束做好。
给 OpenClaw 和 QVeris 的具体建议
这次测试后,我觉得最值得做的不是继续追问“Gemma 4 12B 到底聪不聪明”,而是把周边工作流补齐。
1. 高频 tool_id 缓存
股票、商品、汇率、天气这类高频能力,不应该每次都从 discover 重新猜。可以维护一份已验证 tool_id 缓存:
| 能力 | 建议缓存 |
|---|---|
| 股票 quote | finnhub_io_api.stock.quote |
| commodity latest rates | commodity_price_api.rates.latest.retrieve... |
| 空气质量 | openweathermap.air_pollution.current.v2_5 |
| 天气 forecast | visualcrossing.timeline.retrieve.v1 |
| 学术论文搜索 | semantic_scholar.paper.search.bulk... |
缓存不是为了绕过 QVeris discovery,而是为了给 agent 一个已验证起点。discover 可以做 fallback,不应该每次都从零开始。
2. 业务层校验必须前置
C03 和 C06 已经说明,只看 HTTP 200 是不够的。需要增加业务层校验:
- 返回
symbol是否等于目标 symbol; - 返回 currency pair 是否等于用户请求;
- 返回工具类型是否和目标能力一致;
- provider payload 里的
success/status/info是否表示业务成功; - 列表结果是否真的包含目标实体;
- 对商品和股票这类数据,字段单位和报价方向是否正确。
Gemma 4 12B 可以参与判断,但这些校验最好做成确定性规则。模型负责解释,系统负责把关。
3. 长结果要有摘要策略
天气和论文搜索都出现了结果过长被截断。Gemma 4 12B 能读截断片段,但长结果场景最好有固定策略:
- 先抽取 top N;
- 保留目标字段;
- 大 JSON 写文件或对象存储;
- 给模型的是摘要,不是完整原文;
- 如果必须完整读取,再分块做局部分析。
这对本地模型尤其重要。虽然 Gemma 4 系列强调长上下文,但本地部署时上下文越长,KV cache、延迟和内存压力都会上来。能摘要就摘要,能结构化就结构化。
4. 商品价格工具要注意成本
这次 commodity price 每次 9.55 credits,而天气、空气质量、股票 quote、论文搜索等工具多数是 1 credit,USD/CNY 是 2.37 credits。商品价格工具不是不能用,但应该在确需实时商品数据时调用,并尽量复用同一次 discover 结果。
如果后续要做自动化行情监控,应该先做成本分层:高频低成本工具可以多调,高成本工具要缓存、聚合或降低频率。
5. OpenClaw CLI compaction 问题要单独修
这次 OpenClaw agent CLI 触发 CLI transcript compaction failed: Already compacted,导致评测最后改走 Ollama API。这个问题和 Gemma 4 12B 本身无关,但会影响大规模自动评测。
在修复前,我会建议:
- 长评测走 Ollama API;
- OpenClaw 会话缩短 workspace/bootstrap;
- 每个案例独立运行,减少 transcript 压力;
- 评测结果落文件,再由 Codex 汇总。
这也是本地 agent 工程化里经常被低估的一点:模型能跑只是第一步,会话管理、日志、工具协议和失败恢复同样重要。
这次实验里 Codex 的角色
这篇实践不是“我手动点点按钮测试 Gemma 4 12B”。事实上,很多工作是 Codex 编排完成的:
- 设计 10 个 QVeris 案例;
- 将需求转成英文 capability query;
- 解析工具参数;
- 尝试候选工具;
- 采集 QVeris credits、耗时、原始结果;
- 调用本地 Gemma 4 12B 获取 token 和速度;
- 生成报告和图表;
- 把飞书文档内容整理成可读文章。
这也说明了我现在对本地模型的一个实际用法:本地模型不一定要单独承担全流程。它可以成为 Codex 编排下的一个可替换执行单元。
更强模型负责规划、纠错、检查边界;本地模型负责低成本执行、草稿生成、结果解释、局部代码生成。这样组合起来,整体会比“只用一个模型做所有事情”更稳定。
我的最终判断
Gemma 4 12B 在这次实践里给我的感觉是:它已经足够进入真实工作流,但还没有到可以放任自流的程度。
它的优点很明确:
- 本地部署方便,Ollama 入口简单;
- 输出速度稳定,约 83 tokens/s;
- 能生成可运行代码,尤其在 prompt 清楚时;
- 能读取 JSON 工具结果;
- 能识别明显的工具错配;
- 对 OpenClaw + QVeris 这种工具增强场景有实际价值;
- 作为本地模型,它可以给隐私、成本和离线能力提供新选择。
它的问题也同样明确:
- prompt 稍微模糊,代码质量就会波动;
- 约束太多时,会牺牲隐性质量,比如分形树视觉效果;
- 自主工具选择能力不能完全信任;
- 长输出会带来明显等待时间;
- 对实时数据,必须依赖 QVeris 这类工具,不能让模型凭记忆回答;
- 业务校验必须工程化,不能只靠模型“看出来”。
如果要把它接入 OpenClaw 和 QVeris,我会给一个保守但正面的结论:
Gemma 4 12B 可以作为 OpenClaw 的本地可用模型选项,适合代码草稿、结构化解释、工具结果摘要和低风险自动化任务;在涉及金融、实时数据、外部 API 和多步骤工具选择时,必须配合 QVeris 的真实数据、Codex 的编排能力,以及确定性的业务校验。
分形树实验让我看到它对 prompt 的敏感性;QVeris 实验让我看到它在结构化结果判断上的可用性。两者合在一起,我更愿意把结论写成一句工程判断:
Gemma 4 12B 可以用,但要放在合适的位置。
它不是替代 Codex 的模型,而是可以被 Codex、OpenClaw、QVeris 调度的本地执行模型。输入给得好,边界设得清,它能完成不少实际任务;输入糊,校验弱,它也会把错误工具结果认真解释成看起来像答案的东西。
这大概就是 12B 本地模型最真实的状态:已经足够有用,但仍然需要工程纪律。