
Ollama 上的 Gemma 4 12B 能直接听语音吗?
上一篇我验证了一个容易被混淆的问题:gemma4:12b 在 Ollama 上能不能直接读 MP4。答案是不能直接读视频文件,稳定路径是先抽帧,再把帧序列作为图片输入。
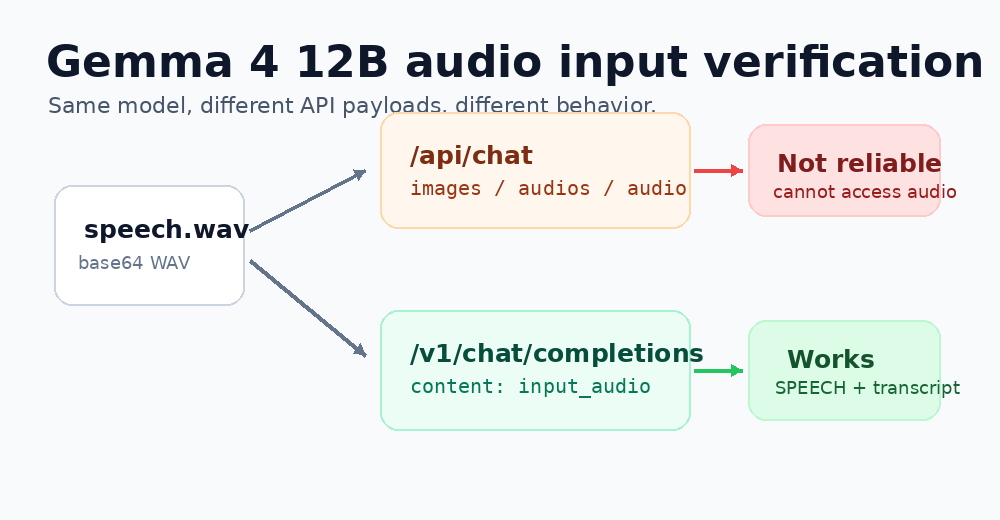
这次换成音频。问题看起来更简单:ollama show gemma4:12b 已经把 audio 列在 capabilities 里,那是不是就可以把一段语音直接丢给 Ollama,让模型转写或理解?
实测之后,答案仍然需要拆成两层:
模型和本地 Ollama 版本声明支持 audio;但在测试机上,Ollama 原生 /api/chat 不能可靠接收音频。真正跑通的是 OpenAI 兼容接口 /v1/chat/completions,并使用 input_audio 内容块。
这篇文章记录完整验证过程。重点不是证明某个模型“很强”或“不强”,而是把工程接入时最容易踩错的那条边界说清楚:模型能力、Ollama 模型元数据、具体 API payload 形态,是三件不同的事。
实验环境
测试环境是一台本地测试机,Ollama 服务跑在默认端口 11434。
$ ssh <测试机> 'hostname; whoami; command -v ollama; ollama --version'
test-machine
alex
/usr/local/bin/ollama
ollama version is 0.30.5模型已经安装:
$ ollama list
NAME ID SIZE MODIFIED
gemma4:12b 4eb23ef187e2 7.6 GB 10 days ago模型元数据显示它确实具备音频能力:
$ ollama show gemma4:12b
Model
architecture gemma4
parameters 11.9B
context length 262144
embedding length 3840
quantization Q4_K_M
requires 0.30.5
Capabilities
completion
vision
audio
tools
thinking这一步只能说明“模型声明有 audio 能力”,还不能说明“当前接口写法可用”。所以后面所有实验都以接口返回和模型行为为准。
第一轮:先用合成音频测接口是否接收
为了排除外部文件问题,我先在测试机上用 Python 标准库生成了两段 WAV:
tone.wav:1.2 秒、16 kHz、单声道、440 Hz 正弦波;silence.wav:同样长度和采样率,但全是静音。
请求目标是两个接口:
- Ollama 原生接口:
POST /api/chat - OpenAI 兼容接口:
POST /v1/chat/completions
原生 /api/chat 的第一种尝试,是把 WAV base64 放进 messages[].images。这个字段名看起来不对,但 Ollama 多模态原生接口长期以 images 作为图片入口;在没有明确音频字段文档可用时,这是一个有必要做的负例验证。
import base64
import json
import urllib.request
from pathlib import Path
BASE = "http://127.0.0.1:11434"
MODEL = "gemma4:12b"
b64 = base64.b64encode(Path("/tmp/tone.wav").read_bytes()).decode()
payload = {
"model": MODEL,
"messages": [
{
"role": "user",
"content": "Listen to this audio. Is it a steady tone or silence? Answer in one short English sentence.",
"images": [b64],
}
],
"stream": False,
"think": False,
"options": {"temperature": 0, "num_predict": 80},
}
req = urllib.request.Request(
BASE + "/api/chat",
data=json.dumps(payload).encode(),
headers={"Content-Type": "application/json"},
)
with urllib.request.urlopen(req, timeout=180) as r:
print(r.read().decode())结果比较微妙:
native /api/chat tone status=200
It is a steady tone.
native /api/chat silence status=200
It is a steady tone.如果只看第一条,很容易误判为“音频通了”。但第二条静音也被回答成 steady tone,说明这组结果不可信。接口返回 200 只能证明 payload 没被直接拒绝,不能证明模型真的听到了音频。
OpenAI 兼容接口的写法更明确,使用 input_audio:
payload = {
"model": "gemma4:12b",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Listen to this audio. Is it a steady tone or silence? Answer in one short English sentence.",
},
{
"type": "input_audio",
"input_audio": {
"data": b64,
"format": "wav",
},
},
],
}
],
"stream": False,
"temperature": 0,
"max_tokens": 80,
"reasoning_effort": "none",
}对 tone.wav,它返回:
openai /v1/chat/completions input_audio tone status=200
It is a steady tone.这看起来比原生接口靠谱一些,但还不够。因为合成音频太简单,模型也可能根据提示或某些文件特征猜答案。于是我继续做了一组更严格的对照。
第二轮:固定标签对照,避免被自然语言回答骗过
第二轮我让模型只能回答四个标签:
SILENCE, TONE, PULSE, CANNOT_ACCESS_AUDIO测试样本包括:
- 连续正弦波;
- 静音;
- 间歇脉冲;
- 完全不传音频。
这个对照实验的结果如下:
native tone status=200 CANNOT_ACCESS_AUDIO
native silence status=200 CANNOT_ACCESS_AUDIO
native pulse status=200 CANNOT_ACCESS_AUDIO
native none status=200 CANNOT_ACCESS_AUDIO
openai tone status=200 PULSE
openai silence status=200 CANNOT_ACCESS_AUDIO
openai pulse status=200 CANNOT_ACCESS_AUDIO
openai none status=200 CANNOT_ACCESS_AUDIO这组结果反而更有价值。它说明:
- 原生
/api/chat基本可以判定没有拿到音频; - OpenAI 兼容接口至少没有完全拒绝
input_audio,但对这种人工合成的短音频,识别并不稳定; - 不能用“HTTP 200 + 看似合理的一句话”作为音频能力验证标准。
到这里,我还不能说“语音输入可用”。我只能说:原生接口不可用;OpenAI 兼容接口有迹象,但需要真实语音样本确认。
第三轮:换成真实英文语音 WAV
测试机上没有安装 espeak、ffmpeg、festival 这类本地语音或转码工具,只有 curl 和 wget:
espeak
espeak-ng
festival
pico2wave
say
ffmpeg
curl /usr/bin/curl
wget /usr/bin/wget所以我下载了一份公开英文 WAV 语音样本到 /tmp/speech.wav,先问模型能否判断这是人声:
curl -L --fail --max-time 30 \
-o /tmp/speech.wav \
https://www.voiptroubleshooter.com/open_speech/american/OSR_us_000_0010_8k.wav对同一个文件分别调用两个接口。
原生 /api/chat,继续用 images 承载 base64 WAV:
native status 200
CANNOT_ACCESS_AUDIOOpenAI 兼容 /v1/chat/completions,使用 input_audio:
openai status 200
SPEECH这一步已经能证明 OpenAI 兼容接口的音频路径不是完全摆设。为了进一步确认它不是只根据 WAV 文件头或提示词猜测,我让它转写开头内容。
请求仍然是同一个 input_audio 格式,只把提示词改成:
Transcribe the first sentence or first 10 words of this audio. If you cannot access audio, say CANNOT_ACCESS_AUDIO.返回结果如下:
The birch canoes slid on the smooth planks. Glue the sheet to the dark blue background. It is easy to tell the depth of a well. These days a chicken leg is a rare dish. Rice is often served in round bowls. The juice of lemons makes fine punch. The box was thrown beside the park truck. The hogs were fed chopped corn and garbage. Four hours of steady work faced us这段内容与常见英文语音测试语料的句子形态一致,而且不是提示词里提供的信息。到这里,可以认为:在测试机上,gemma4:12b 通过 OpenAI 兼容接口确实可以处理真实语音输入。
第四轮:排除原生接口还有别的音频字段
最后我又试了两个更像音频的字段名:
messages[].audiosmessages[].audio
payload 形态大致如下:
msg = {
"role": "user",
"content": "Transcribe the first sentence or first 10 words of this audio. If you cannot access audio, say CANNOT_ACCESS_AUDIO.",
"audios": [b64],
}结果仍然是否定的:
FIELD audios STATUS 200
I am unable to transcribe the audio because I do not have access to any audio file or input in your message.
FIELD audio STATUS 200
I'm sorry, but I don't have access to an audio file to transcribe.这说明,在当前这台机器的 Ollama 0.30.5 + gemma4:12b 组合上,不能指望原生 /api/chat 自动识别这些音频字段。至少从这次实测看,稳定路径只有 OpenAI 兼容接口。
最终可用写法
后续如果要在代码里调用,建议固定用下面这个形态:
import base64
import json
import urllib.request
from pathlib import Path
base_url = "http://<测试机>:11434"
model = "gemma4:12b"
audio_b64 = base64.b64encode(Path("speech.wav").read_bytes()).decode()
payload = {
"model": model,
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Transcribe this audio. If you cannot access audio, say CANNOT_ACCESS_AUDIO.",
},
{
"type": "input_audio",
"input_audio": {
"data": audio_b64,
"format": "wav",
},
},
],
}
],
"stream": False,
"temperature": 0,
"max_tokens": 200,
"reasoning_effort": "none",
}
req = urllib.request.Request(
base_url + "/v1/chat/completions",
data=json.dumps(payload).encode(),
headers={"Content-Type": "application/json"},
)
with urllib.request.urlopen(req, timeout=240) as r:
print(r.read().decode())返回结构是 OpenAI 兼容格式:
{
"id": "chatcmpl-529",
"object": "chat.completion",
"model": "gemma4:12b",
"choices": [
{
"message": {
"role": "assistant",
"content": "The birch canoes slid on the smooth planks..."
},
"finish_reason": "length"
}
]
}这次实验里的几个教训
第一,不要把 ollama show 里的 capability 当成最终接口契约。它很有用,能告诉你模型大体支持什么;但真正接入时,仍然要验证具体 API 字段和 payload 形态。
第二,验证多模态输入时,一定要设计负例。tone.wav 的第一轮测试之所以危险,是因为它返回了一句看似正确的 “It is a steady tone.”。如果没有紧接着测 silence.wav,很容易得出错误结论。
第三,对语音输入来说,“能判断是 SPEECH”还不够。最好再做一次转写或内容理解测试,确认模型确实从音频里读到了内容。
第四,原生接口和 OpenAI 兼容接口不能混为一谈。这次的实际结论不是“gemma4:12b 在 Ollama 上随便怎么传都能听语音”,而是更具体:
在测试机的 Ollama 0.30.5 上,gemma4:12b 可以通过 /v1/chat/completions 的 input_audio 接收 WAV 语音输入;原生 /api/chat 的 images、audios、audio 写法都不能作为可靠方案。
这句话看起来啰嗦,但工程上就该这么写。少一个限定条件,后面就可能多一个排查小时。