Ollama 上的 Gemma 4 12B 能直接读视频吗?
古董级程序员,大厂出来后一直在创业公司,现在仍在一线做 AI 相关的工程。更完整的技术记录写在微信公众号「字与码」:工作经历、对新工具的看法,以及这些年踩过的坑,会不定期发在那里。若这篇对你有用,欢迎顺手关注。
本周我想确认一个看起来很简单、实际很容易被混淆的问题:Ollama 上的 gemma4:12b 能不能直接把 MP4 当输入?
官方资料里,Gemma 4 12B 属于多模态模型,确实具备基于帧序列理解视频的能力;但工程落地时还有另一层边界:本地推理框架到底接收什么格式。最后的实测结果很明确:在 Ollama 0.30.5 里,MP4 不能直接塞进接口,路径也不会被自动读取;可行方案是先抽帧,再把连续帧作为多张图片输入。
这件小事值得写下来,因为“模型支持视频”和“API 支持上传视频文件”经常被说成同一句话。它们不是一回事。
结论先行
本次实验的结论可以分成两层:
- Gemma 4 12B 模型层面具备视频理解能力。Google 的 Gemma 4 model card 明确说明:所有 Gemma 4 模型都支持图像输入,并且可以“把视频作为帧序列处理”;E2B、E4B 和 12B 还支持音频输入,视频建议按 1 FPS 处理,最长约 60 秒。
- 本地实验机上的 Ollama 接口不能直接把 MP4 当作原生视频输入。Ollama 当前官方 Vision 文档要求通过
images数组传入图片;REST API 需要 base64 图片。实际把 MP4 base64 放进images字段会报错:400 Failed to load image or audio file。
因此,面向工程落地的正确说法是:
在 Ollama 上用 gemma4:12b 分析视频,推荐流程不是“直接传 MP4”,而是“视频抽帧 -> 多图输入 -> 让模型基于连续帧做理解”。
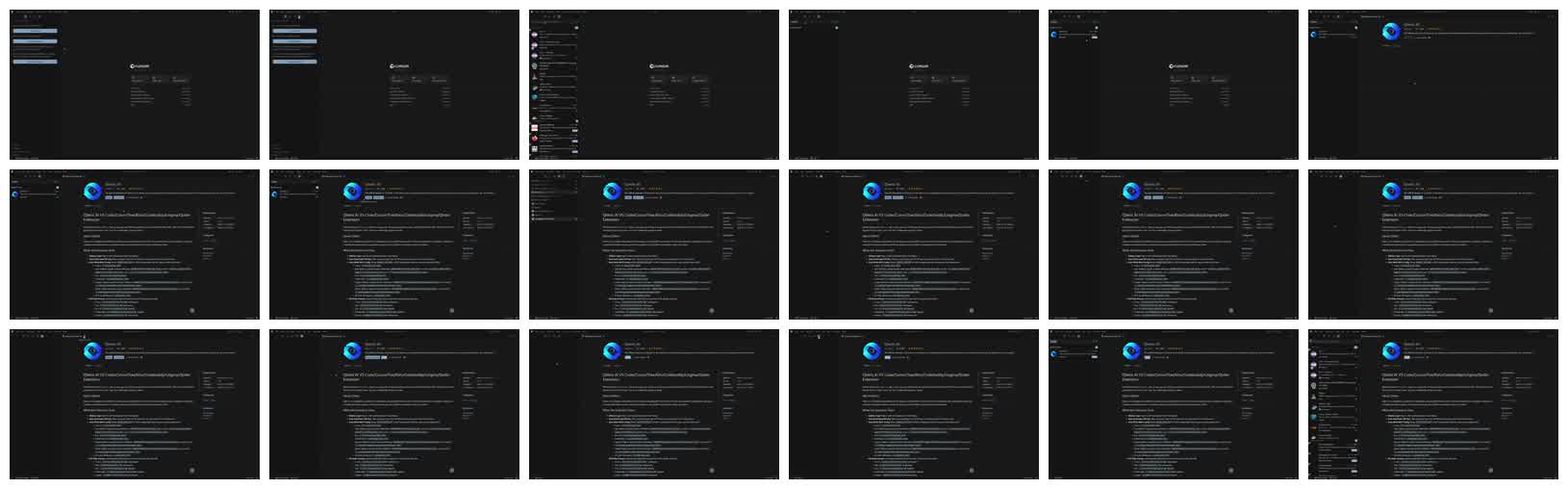
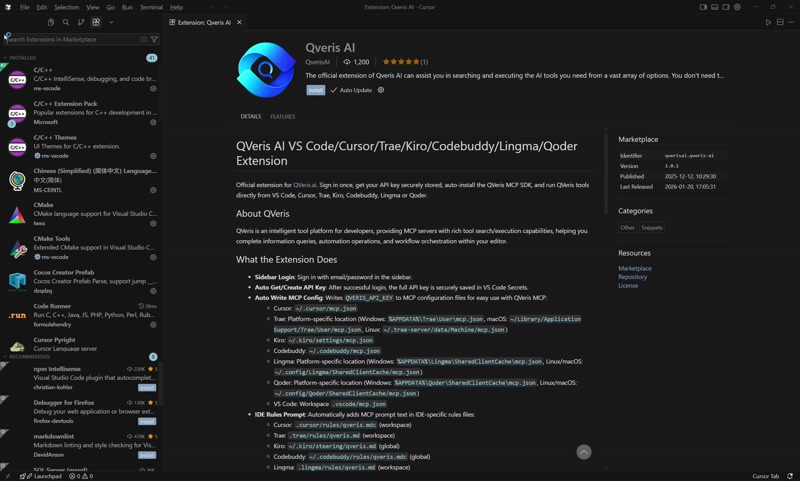
图 1:2.mp4 按 0.5 FPS 抽出的 18 张连续帧。可以看到视频是在 Cursor 扩展市场中搜索、查看并安装一个扩展。
为什么要做这个实验
多模态模型的宣传材料里,“支持视频”通常有几种不同含义:
- 模型训练和结构支持理解帧序列、时间关系、音频;
- 推理框架支持把视频文件解码成帧并交给模型;
- API 支持直接上传 MP4/MOV/WebM;
- 客户端工具自动完成抽帧、压缩、拼接 prompt;
- 模型只是能接收多张图片,视频处理由用户自己完成。
这几层能力很容易被混在一起。对实际研发来说,差异很关键:如果线上服务只支持图片数组,那么“模型支持视频”并不等于“接口可以直接传视频文件”。本次实验就是要验证一台本地实验机上的真实可用边界,并给出可复用的工程路径。
官方资料梳理
Gemma 4 12B:模型支持帧序列视频理解
Google Gemma 4 model card 写到,Gemma 4 的扩展多模态能力包括 Text、Image、Video 和 Audio,其中音频原生支持出现在 E2B、E4B 和 12B 模型上。它还进一步说明:所有模型都支持图片输入,并能把视频作为帧来处理;音频最长 30 秒,视频在 1 FPS 假设下最长约 60 秒。
Google Developers Blog 的 Gemma 4 12B 开发者指南也给了一个很具体的示例:他们处理一段约 5 分钟的视频时,先按 1 FPS 抽出 313 帧,再把帧、音频和问题一起喂给 Gemma 4 12B。这个例子说明,Gemma 4 12B 的视频理解在实践上仍然经常表现为“帧序列 + prompt + 可选音频”的组合。
Ollama:当前公开接口主要是图片输入
Ollama 的 gemma4 模型页把 gemma4:12b 的输入标注为 Text, Image,上下文窗口 256K。Ollama Vision 文档也明确给出当前用法:视觉模型通过 images 数组接收图片,SDK 可以传路径、URL 或 bytes,REST API 则需要 base64 编码图片。
换句话说,在 Ollama 这层,gemma4:12b 的可用视觉入口是“图片”,而不是“视频文件”。如果要处理视频,调用方需要先抽帧。
实验环境
本地实验机上的 Ollama 和模型信息如下:
$ ollama --version
ollama version is 0.30.5
$ ollama list
NAME ID SIZE MODIFIED
gemma4:12b 4eb23ef187e2 7.6 GB 9 days ago
...
$ ollama show gemma4:12b
Model
architecture gemma4
parameters 11.9B
context length 262144
quantization Q4_K_M
requires 0.30.5
Capabilities
completion
vision
audio
tools
thinking测试素材信息:
2.mp4: ISO Media, MP4 Base Media v1
video: h264, 2560x1540, 30 fps
audio: aac
duration: 35.300000 seconds
size: 2002349 bytes实验一:只把 MP4 路径写进 prompt
先做一个最朴素的尝试:
ollama run gemma4:12b "请用一句话回复:你能看见这个视频文件吗?/tmp/gemma4-video-2.mp4"模型回复的大意是:它无法访问本地文件系统路径,除非文件内容被实际上传到对话中。
这个结果符合预期。单纯把 /tmp/gemma4-video-2.mp4 写进 prompt,本质上只是给模型一段文本,Ollama CLI 没有自动把这个 MP4 解码并加载为视频输入。
实验二:把 MP4 base64 放进 images 字段
接着尝试 REST API,把 MP4 文件 base64 编码后放进 images 数组:
import base64
import json
import urllib.request
import urllib.error
mp4 = base64.b64encode(open("/tmp/gemma4-video-2.mp4", "rb").read()).decode()
payload = {
"model": "gemma4:12b",
"prompt": "请描述这个视频。",
"images": [mp4],
"stream": False,
"options": {"num_predict": 80},
}
req = urllib.request.Request(
"http://localhost:11434/api/generate",
data=json.dumps(payload).encode(),
headers={"Content-Type": "application/json"},
)
try:
with urllib.request.urlopen(req, timeout=90) as r:
print(r.read().decode())
except urllib.error.HTTPError as e:
print("HTTPError", e.code, e.read().decode())返回结果:
{
"error": "{\"error\":{\"code\":400,\"message\":\"Failed to load image or audio file\",\"type\":\"invalid_request_error\"}}"
}这一步是整个实验最关键的负例。它说明:Ollama 的 images 字段不会把 MP4 当视频处理,也不会自动抽帧。
实验三:抽帧后作为多张图片输入
既然官方资料和 Ollama 文档都指向“帧序列”,下一步就是手动抽帧。2.mp4 有 35.3 秒,如果按 1 FPS 会得到 35 张图;为了控制单次请求的视觉 token 和延迟,我在主实验里按 0.5 FPS 抽出 18 张图:
ffmpeg -hide_banner -loglevel error \
-i 2.mp4 \
-vf fps=0.5,scale=800:-1 \
/tmp/gemma4-video2-frames/frame_%03d.jpg抽帧结果:
frame_001.jpg 800x481
frame_002.jpg 800x481
...
frame_018.jpg 800x481第 1 帧:
第 9 帧:
第 18 帧:
调用 /api/chat,把 18 张图放进 messages[].images:
import base64
import json
import pathlib
import urllib.request
frames = sorted(pathlib.Path("/tmp/gemma4-video2-frames").glob("frame_*.jpg"))
imgs = [base64.b64encode(p.read_bytes()).decode() for p in frames]
payload = {
"model": "gemma4:12b",
"stream": False,
"think": False,
"messages": [
{
"role": "user",
"content": (
"这些图片是同一个 35.3 秒视频按 0.5 FPS 抽取的连续帧,按时间顺序排列。"
"请只输出最终答案,不要输出思考过程。"
"用中文概括视频内容,并指出画面里的主要对象、关键变化和不确定点。"
),
"images": imgs,
}
],
"options": {
"num_predict": 420,
"temperature": 0.2,
},
}
req = urllib.request.Request(
"http://localhost:11434/api/chat",
data=json.dumps(payload).encode(),
headers={"Content-Type": "application/json"},
)
with urllib.request.urlopen(req, timeout=180) as r:
data = json.loads(r.read().decode())
print(data["message"]["content"])模型输出摘要如下:
这段视频展示了用户在 Cursor 编辑器中安装 “Qweris AI” 扩展包的过程。主要对象包括 Cursor 编辑器界面、Extensions 侧边栏和 “Qweris AI” 扩展详情页。关键变化是:用户先在扩展市场中搜索 “Qweris”,然后打开 “Qweris AI” 详情页,最后点击蓝色的 “Install” 按钮开始安装。由于视频在点击安装后即结束,无法确认扩展是否安装完成或后续配置步骤。
这说明抽帧后的多图输入是可行的:模型不仅能识别视频画面主体,还能把连续帧串成一个相对完整的操作流程。
不过,这次实验也暴露了两个注意点:
gemma4:12b默认有 thinking 行为。第一次num_predict设置过小,token 预算被 thinking 消耗,导致message.content为空,但message.thinking里已经识别出了画面内容。后续加上"think": false后才得到干净的最终回答。- 0.5 FPS 已经足够覆盖这段扩展安装流程的关键节点,但如果要判断安装后的状态、弹窗细节或终端输出,仍然需要提高帧率或对关键区域做局部裁剪。
实验结果有什么价值
1. 澄清“支持视频”的真实工程含义
模型卡里的“video understanding”并不自动等价于“服务端 API 可以直接接收 MP4”。在本次环境中,真实边界是:
MP4 直接输入:不可行
MP4 路径输入:不可行,只是文本
抽帧为 JPG/PNG 后输入:可行这对服务设计很重要。如果要在产品里写“支持视频分析”,就应该明确实现链路:上传视频、抽帧、采样、压缩、调用 VLM、聚合结果,而不是只依赖模型名。
2. 给本地私有视频分析提供了低成本路径
本次使用的 gemma4:12b 是本地 Ollama 部署,视频内容不需要发到云端。对以下场景有实际价值:
- 屏幕录制内容摘要;
- Web 产品操作录像 QA;
- 监控片段初筛;
- 教学视频片段说明;
- 自动生成视频章节草稿;
- 会议或演示录屏的视觉结构化。
如果视频短、画面变化不剧烈,抽 1 FPS 到 2 FPS 往往已经足够。相比完整视频编码输入,抽帧方案更透明,也更容易控制成本。
3. 暴露了本地 VLM 工作流的关键参数
这次实验里最影响结果的不是模型能不能“看见”,而是下面这些工程参数:
- 抽帧频率:静态 UI 可用 1 FPS;快速动作、体育、手势、游戏可能需要 3-10 FPS。
- 分辨率:640px 宽适合概要;OCR、代码、表格需要更高分辨率或局部裁剪。
- 帧数量:帧越多,视觉 token 越多,延迟和显存压力越高。
- thinking 开关:需要稳定接口输出时,建议显式设置
think: false。 - 输出长度:
num_predict太小会截断回答,尤其是 thinking 模型。
与同级开源模型的比较
下面的比较只讨论“视频/多帧理解能力和工程使用方式”,不是完整模型排行榜。除 Gemma 4 12B 外,其他模型未在本次本地环境逐一实测,依据为官方模型卡、论文或项目文档。
| 模型 | 规模定位 | 视频能力描述 | 工程入口 | 适合场景 | 注意点 |
|---|---|---|---|---|---|
| Gemma 4 12B | 约 12B,本次实测 Q4_K_M 7.6GB | Google 文档说明可按帧处理视频,12B 支持音频输入 | 在 Ollama 上主要走图片数组;直接 MP4 不可行 | 本地短视频摘要、屏幕录制分析、图像+文本推理 | Ollama 接口层需要自行抽帧;thinking 需要控制 |
| Qwen2.5-VL-7B | 7B | 官方资料强调长视频理解,可处理超过 1 小时视频,并能定位事件片段 | Transformers / qwen-vl-utils 支持视频加载;具体部署框架不同 | 长视频检索、事件定位、文档/图表/OCR 混合任务 | 7B 版质量和 72B 有差距;视频链路依赖推理框架 |
| Qwen3-VL-8B / 32B | 8B 到 32B | 技术报告称原生 256K 多模态上下文,集成文本、图像和视频,强化时空建模 | Transformers、vLLM 等生态逐步支持 | 新项目优先评估;长上下文视频、复杂多图推理 | 截至 2026-06-15,需要关注本地框架成熟度和显存 |
| MiniCPM-V 4.5 | 8B | 官方模型卡强调高 FPS 和长视频理解,最高可到 10 FPS,视频 token 压缩效率高 | Hugging Face / Ollama 均有相关模型页 | 边缘部署、移动端、本地高性价比视频理解 | 生态和工具链不如 Qwen 广;具体视频输入仍需看运行时 |
| GLM-4.1V-9B-Thinking | 9B | 面向多模态推理,覆盖图像、视频、文档、GUI agent | Hugging Face / Xinference 等 | 需要推理链的图像/视频问题、中文任务 | thinking 模型输出控制和延迟要重点评估 |
| LLaVA-OneVision-7B | 7B | 统一支持单图、多图和视频理解,是较早的开源视频 VLM 代表 | Transformers / LLaVA 工具链 | 学术复现、轻量视频理解 baseline | 相比 2026 年新模型,OCR、长视频和工具能力可能落后 |
| Llama 4 Scout | 17B active / 109B total,不算同显存级别 | Meta 称其为原生多模态;Llama 文档显示文本 + 最多 5 图输入,文本输出 | Ollama 可跑 vision;官方模型卡偏图像输入 | 多图推理、长上下文文本任务 | 规模和资源需求明显更高;不适合作为 12B 级直接替代 |
一个实用判断是:
- 只想在现有 Ollama 环境上快速做视频摘要:继续用
gemma4:12b,自己抽帧。 - 重点是长视频事件定位:优先看 Qwen2.5-VL / Qwen3-VL。
- 重点是小模型高 FPS 视频理解:重点评估 MiniCPM-V 4.5。
- 重点是复杂视觉推理和中文问答:可以评估 GLM-4.1V-9B-Thinking。
- 需要稳定工程生态:Qwen 系列和 Ollama 官方支持模型通常更容易集成。
实用推荐:如何把视频输入做成可用服务
推荐一:先不要追求“原生 MP4 输入”
在当前本地开源生态里,抽帧仍然是最稳妥的抽象层。它有几个好处:
- 可控:能明确控制帧率、分辨率、最大帧数;
- 可缓存:同一视频抽帧后可以重复问答;
- 可解释:出现误判时能回看具体帧;
- 可替换:底层模型从 Gemma 换成 Qwen/MiniCPM/GLM 时,上层视频预处理不用大改。
推荐二:按任务选择抽帧策略
| 任务 | 建议抽帧 | 分辨率 | Prompt 重点 |
|---|---|---|---|
| 屏幕录制摘要 | 1 FPS | 640-960px 宽 | 页面、模块、操作变化 |
| 教学/演示视频 | 1-2 FPS | 720-960px 宽 | 步骤、关键画面、章节 |
| 监控片段初筛 | 1-3 FPS | 640-1280px 宽 | 人、车、异常动作 |
| 快速动作/游戏 | 3-10 FPS | 640-960px 宽 | 时间顺序、动作变化 |
| OCR/代码/表格 | 低 FPS + 高分辨率或局部裁剪 | 1080p 或裁剪 | 文字读取、字段抽取 |
推荐三:在 prompt 里显式声明帧序列
不要只说“描述这些图片”。更好的写法是:
这些图片是同一个视频按时间顺序抽取的连续帧。
请基于帧序列概括视频内容,指出主要对象、动作变化和不确定之处。
如果画面变化很小,请明确说明它基本是静态画面。这能减少模型把帧当成无关图片集合的概率。
推荐四:输出结构化结果,便于产品消费
对服务化场景,建议让模型输出 JSON:
{
"summary": "一句话摘要",
"main_objects": ["对象1", "对象2"],
"timeline": [
{"time_range": "0-3s", "event": "事件描述"},
{"time_range": "4-8s", "event": "事件描述"}
],
"uncertainties": ["不确定点"]
}实际实现时可以先按固定 fps 抽帧,并把帧号映射回时间戳。例如本次 0.5 FPS 采样下,frame_009.jpg 大约对应第 18 秒附近。
可复用的最小流程
1. 抽帧
VIDEO=2.mp4
OUT=/tmp/video-frames
mkdir -p "$OUT"
ffmpeg -hide_banner -loglevel error \
-i "$VIDEO" \
-vf fps=0.5,scale=800:-1 \
"$OUT/frame_%03d.jpg"2. 调 Ollama
import base64
import json
import pathlib
import urllib.request
frames = sorted(pathlib.Path("/tmp/video-frames").glob("frame_*.jpg"))
imgs = [base64.b64encode(p.read_bytes()).decode() for p in frames]
payload = {
"model": "gemma4:12b",
"stream": False,
"think": False,
"messages": [
{
"role": "user",
"content": (
"这些图片是同一个视频按时间顺序抽取的连续帧。"
"请用中文输出:1. 摘要;2. 主要对象;3. 明显变化;4. 不确定点。"
),
"images": imgs,
}
],
"options": {"temperature": 0.2, "num_predict": 512},
}
req = urllib.request.Request(
"http://localhost:11434/api/chat",
data=json.dumps(payload).encode(),
headers={"Content-Type": "application/json"},
)
with urllib.request.urlopen(req, timeout=180) as r:
print(json.loads(r.read().decode())["message"]["content"])局限与后续实验
本次实验只验证了一个 35.3 秒的屏幕录制视频,内容是 IDE 扩展市场里的搜索、详情查看和安装点击。因此结论不能直接外推到所有视频任务。下一步建议补充:
- 动态视频测试:例如人物动作、车辆移动、手势、游戏画面,观察模型对时序变化的理解。
- 不同 fps 对比:1 FPS、2 FPS、5 FPS、10 FPS 的准确率、延迟、显存占用。
- 不同模型对比实测:同一视频分别跑 Gemma 4 12B、MiniCPM-V 4.5、Qwen2.5-VL-7B、GLM-4.1V-9B。
- 音频链路测试:从 MP4 抽出 WAV,验证 Ollama 当前对 Gemma 4 12B 音频输入的真实支持程度。
- 结构化输出稳定性:多次运行同一视频,检查 JSON 格式、关键对象、时间线是否稳定。
总结
这次实验的核心价值,不是证明 Gemma 4 12B “强不强”,而是把一个容易被误解的产品问题拆开了:
模型支持视频理解,不代表当前部署接口支持直接上传视频文件。
在这台本地实验机的 Ollama 0.30.5 环境下,gemma4:12b 的可行方案是抽帧后作为多图输入。这个方案虽然不如“直接传 MP4”优雅,但胜在透明、稳定、可控,适合快速构建本地视频摘要和视觉 QA 原型。
对研发和产品决策来说,这个结果也给出了清晰建议:如果目标是短视频和屏幕录制摘要,现有 gemma4:12b + ffmpeg 抽帧 + Ollama images 已经可以开始用;如果目标是长视频、动作事件定位或高 FPS 理解,则应进一步评估 Qwen3-VL、Qwen2.5-VL、MiniCPM-V 4.5 等更偏视频任务的开源模型。
参考资料
- Ollama Gemma 4 模型页:https://ollama.com/library/gemma4
- Ollama Vision 文档:https://docs.ollama.com/capabilities/vision
- Google Gemma 4 model card:https://ai.google.dev/gemma/docs/core/model_card_4
- Google Gemma 4 12B Developer Guide:https://developers.googleblog.com/gemma-4-12b-the-developer-guide/
- Google Gemma + Ollama 集成文档:https://ai.google.dev/gemma/docs/integrations/ollama
- Qwen2.5-VL Technical Report:https://arxiv.org/abs/2502.13923
- Qwen2.5-VL 官方博客:https://qwen.ai/blog?id=qwen2.5-vl
- Qwen3-VL Technical Report:https://arxiv.org/abs/2511.21631
- Qwen3-VL GitHub:https://github.com/QwenLM/Qwen3-VL
- MiniCPM-V GitHub:https://github.com/openbmb/MiniCPM-V
- MiniCPM-V 4.5 Hugging Face:https://huggingface.co/openbmb/MiniCPM-V-4_5
- GLM-V GitHub:https://github.com/zai-org/GLM-V
- LLaVA-OneVision 项目介绍:https://llava-vl.github.io/blog/2024-08-05-llava-onevision/
- Llama 4 model card:https://www.llama.com/docs/model-cards-and-prompt-formats/llama4/