原创 · 约 9 分钟阅读 · 阅读 --
Last updated on
House Prices:第一次提交Top 11%
竞赛地址:House Prices - Advanced Regression Techniques
教程地址就不贴了,百度随便搜了一个,做了一半发现代码不全,比较坑人,正好可以深入了解一下,这么简单的例子自己应该可以独立完成吧?
其实过程很简单,总结一下就是下面几部分:
- 了解分析数据,也就是EDA的过程,这个竞赛的数据有81个属性,看了很多入门的例子,重点都会在这个阶段,会详细介绍如何分析这些属性。
- 补全空值
- 生成训练和预测的输入数据
- 选择模型进行预测
- 保存结果,提交
下面做一些简单的说明,代码比较简单,具体可以参加notebook:House Prices: First commit got 11%
一开始查看一下输入文件,如果打算在本地运行,这里可以判断一下是否kangle的环境,然后设置一下文件名,在kangle的notebook,输入文件的路径是这样的:
/kaggle/input/house-prices-advanced-regression-techniques/sample_submission.csv
/kaggle/input/house-prices-advanced-regression-techniques/data_description.txt
/kaggle/input/house-prices-advanced-regression-techniques/train.csv
/kaggle/input/house-prices-advanced-regression-techniques/test.csv然后读入文件:
file_train_in = '/kaggle/input/house-prices-advanced-regression-techniques/train.csv'
file_test_in = '/kaggle/input/house-prices-advanced-regression-techniques/test.csv'
train = pd.read_csv(file_train_in)
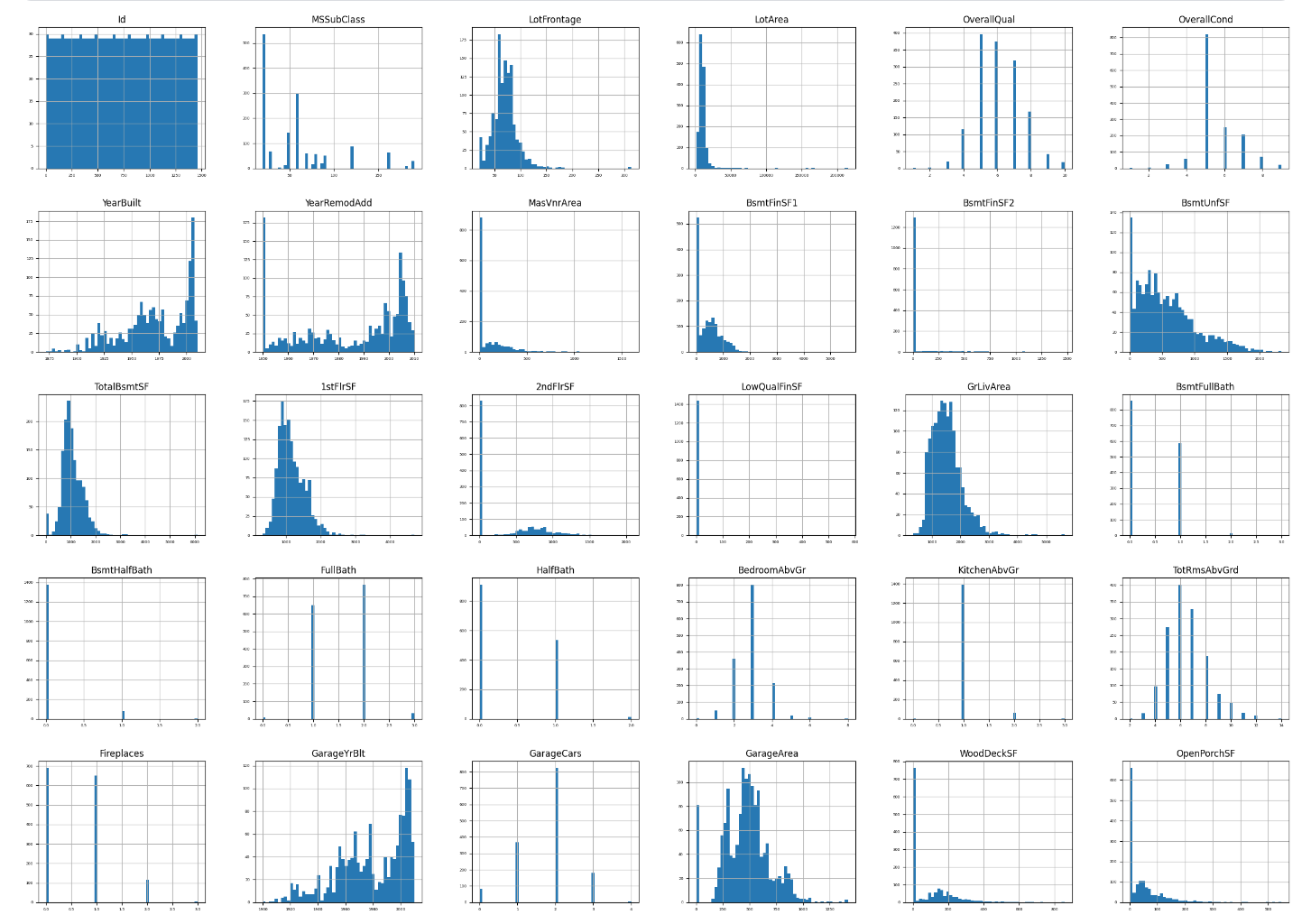
test = pd.read_csv(file_test_in)train数据集有1460行,81列,notebook中后面有比较大的篇幅是分析这些数据,这里就略去了,放一张所有特征直方图汇总的截图,分析数据的时候直方图还是比较有用的:
接下来补全空值,对于数值类型和字符类型处理不同:
str=train.select_dtypes("object")
for column in str:
train.fillna({column:train[column].mode()[0]}, inplace=True)
test.fillna({column:train[column].mode()[0]}, inplace=True)
num=train.select_dtypes(["float64","int64"]).drop("SalePrice",axis=1)
for column in num:
train.fillna({column:train[column].median()}, inplace=True)
test.fillna({column:train[column].median()}, inplace=True) 生成训练数据和特征
data=pd.get_dummies(train,columns=str.columns)
data_test=pd.get_dummies(test,columns=str.columns)
train_features = data.columns.difference(['SalePrice'])
test_features = data_test.columns.difference(['SalePrice'])
features = train_features.intersection(test_features)
target = 'SalePrice'
x = data[features]
y = data[target]
test_x = data_test[features]
categorical_features_indices = np.where(x.dtypes == 'object')[0]训练和预测,用的是CatBoostRegressor模型,可以看到这一步挺简单的,直接用的单一模型,最后结果已经不错了。
model = CatBoostRegressor(verbose = False, loss_function='RMSE', cat_features=categorical_features_indices)
model.fit(x, y)
test_pred = model.predict(test_x)保存和提交
test_id = test['Id']
submission = pd.DataFrame(test_id, columns = ['Id'])
submission['SalePrice'] = test_pred
submission.head()
submission.to_csv("submission.csv", index = False, header = True)排名成绩