
本地四个开源模型跑了一遍:Qwen3、Gemma 4 在 8GB 显存上的真实表现
上一篇文章把本地开源模型的运行方式先搭起来了:Ollama 放在 WSL 里跑,模型文件放在 Linux 用户目录,llama.cpp 先做 CPU 构建,后面再补 CUDA 版本。这一篇不谈概念,直接把四个模型拉下来跑一轮,看看它们在一块 8GB 显存的移动端 GPU 上到底能不能成为日常工具。
测试对象是 qwen3:4b、qwen3:8b、gemma4:e4b 和 gemma4:12b。它们都不是巨无霸模型,理论上很适合个人开发机。但真正用起来,差异会比参数规模更有意思:有的快,有的稳,有的多模态能力更值得留在本地,有的默认模板需要特别注意。
先说结论
如果只想在本地留一个日常文字模型,我会先选 qwen3:8b。它的中文输出更稳,显存压力还在 RTX 4060 Laptop 8GB 的可接受范围内,热启动后响应也足够快。
如果要做轻量分类、标题生成、短文本改写,qwen3:4b 更省资源。它不适合承担复杂推理,但非常适合做流水线里的小节点。
如果要看图片、读截图、解释图表,gemma4:e4b 比我预期更实用。它在这台机器上的速度明显好于 gemma4:12b,图像理解结果也已经能用于日常辅助。
gemma4:12b 的优势是描述更细,缺点也很直接:慢,冷启动明显慢,长输出更容易把耐心耗掉。它适合偶尔处理更复杂的视觉理解,不适合每次都默认调用。
测试机器
这轮测试使用的是同一台本地开发机:
- 宿主机内存:64GB
- WSL 分配内存:32GB
- WSL 系统:Ubuntu 26.04 LTS
- GPU:NVIDIA GeForce RTX 4060 Laptop GPU,8GB 显存
- Ollama:0.30.10
- llama.cpp:本轮先使用 CPU 构建版本
- 模型目录:
~/.ollama/models
Ollama 服务启动后,能在 WSL 内识别到 NVIDIA GPU。nvcc 是否存在不影响 Ollama 推理,但会影响自己编译 CUDA 版 llama.cpp。所以这篇里的 llama.cpp 对比只看 CPU 基线,不把它当作最终性能结论。
四个模型的第一轮数据
先看最直观的结果。下面这些数据不是严谨实验室基准,而是同一台机器、同一套运行环境里,为了判断日常可用性做的第一轮实测。
| 模型 | 本地大小 | 冷启动加载 | 热启动加载 | 生成速度 | 热运行显存 | 第一印象 |
|---|---|---|---|---|---|---|
qwen3:4b | 2.5GB | 约 12.3s | 0.13s - 0.16s | 约 38 - 43 tok/s | 约 2.7GB - 2.8GB | 很快,适合轻任务 |
qwen3:8b | 5.2GB | 约 16.8s | 约 0.23s | 约 22 - 26 tok/s | 约 4.9GB | 中文日常主力 |
gemma4:e4b | 9.6GB | 约 14.4s | 0.66s - 0.72s | 约 54 - 56 tok/s | 约 3.1GB | 多模态性价比高 |
gemma4:12b | 7.6GB | 约 43.0s | 约 0.72s | 约 7 - 9 tok/s | 约 5.8GB | 更细,但慢 |
几个现象比较值得记:
第一,模型文件大小和实际显存占用并不是简单线性关系。gemma4:e4b 本地文件更大,但热运行显存占用反而比 qwen3:8b 更低。
第二,冷启动和热启动是两种完全不同的体验。只要模型还在内存里,qwen3:8b 的加载几乎可以忽略;但第一次调用时,十几秒的等待仍然明显。
第三,gemma4:12b 的速度决定了它不能被当作默认入口。它可以作为“需要更细致视觉描述时再调用”的模型,而不是每次都放在工作流第一步。
Qwen3 的默认输出要小心
Qwen3 这两个模型有一个很容易误判的问题:默认调用时,回答可能进入 thinking 字段,response 为空。第一次看到这个现象时,很容易以为模型没有输出,其实它是在按模板走思考通道。
qwen3:8b 默认调用时,曾经出现过 response 为空、thinking 很长,并且因为长度限制停止的情况。加上 think:false 后,短中文回答就正常了:
本地运行小模型可以快速响应,无需依赖网络,适合日常开发中的即时帮助。它占用资源少,能够在本地设备上流畅运行,不影响其他任务。同时,本地模型能保护用户数据隐私,更适合处理敏感信息。这意味着,后续如果把 Qwen3 接入脚本或工具,不应该只检查“接口是否成功”,还要检查输出字段。对大多数日常工具而言,我会默认关闭思考输出,除非任务明确需要展示推理过程。
一个可复用的调用习惯是:
curl http://127.0.0.1:11434/api/chat \
-H 'Content-Type: application/json' \
-d '{
"model": "qwen3:8b",
"messages": [
{"role": "user", "content": "用三句话说明本地小模型适合做什么。"}
],
"think": false,
"stream": false
}'在工程里,这种细节比“模型能不能跑起来”更重要。模型能跑,只代表环境通了;输出字段稳定,才代表它能进入自动化流程。
Gemma 4 的多模态更像实用工具
这轮最值得保留的是 Gemma 4 的图像理解能力。
我用同一张科技风格插图测试 gemma4:e4b 和 gemma4:12b。gemma4:e4b 在 /api/chat 里配合 think:false 后,能稳定给出中文描述,能识别人物、电脑、屏幕、CUDA、模型构建、AI Pipeline 等画面元素。它的速度大约 56 tok/s,体感非常接近日常可用。
gemma4:12b 的描述更细,会主动概括画面风格、屏幕内容、背景里的技术元素和整体主题。但代价是速度明显下降,同样的图像描述耗时超过 40 秒。它不是不能用,而是要放对位置。
补测了一轮更具体的多模态输入后,结论更清楚:
| 测试 | 输入方式 | 模型 | 结果 | 耗时 |
|---|---|---|---|---|
| 单张图片识别 | /api/chat 的 images 字段 | gemma4:e4b | 能识别开发者、终端、GPU、CUDA、WSL、AI Pipeline 等元素,并能判断适合的文章场景 | 约 126s,主要慢在首次加载和图像处理 |
| 多帧视频理解 | 先用 ffmpeg 从真实视频抽取低隐私帧,再把多张帧图作为图片序列输入 | gemma4:e4b | 能判断视频主题、逐帧内容、时间线和局限,适合做非实时视频内容分析 | 约 79s |
单张图片测试用的是下面这张图。它不是随便找的一张装饰图,而是包含了人物、终端、GPU 监控、CUDA、WSL、AI Pipeline 等多个可被模型识别的元素,适合用来检查模型是否真的在读图,而不是只根据 prompt 猜测。

这次我没有只让它“描述图片”,而是让它按照固定字段输出。完整 prompt 是:
请观察这张图片,并按下面格式输出:
1. 一句话主题:概括图片在表达什么。
2. 可见元素:列出你确实能看到的对象、界面或文字。
3. 技术信息:判断图片和哪些本地模型、GPU、WSL、CUDA 或开发环境主题有关。
4. 适合用途:说明它适合放在什么文章里。
5. 不确定点:明确说明哪些内容无法仅凭图片确认。
请只根据图片回答,不要编造看不到的信息。这是 gemma4:e4b 返回的原始结果文本:
1. 一句话主题:这张图片展示了一个开发者在一个多屏幕、高性能的计算环境中,使用WSL和CUDA技术栈进行人工智能模型开发与部署的过程。
2. 可见元素:
* **人物:** 一位坐在电脑前工作的年轻人。
* **硬件设备:** 多个显示器(至少三个),键盘,鼠标,以及一张桌面工作台面。
* **软件界面/文字信息:**
* **左侧屏幕:** 显示GPU性能监控仪表盘,包含GPU名称、风扇转速、温度、内存和利用率等指标。
* **中央屏幕(终端):** 一个命令行界面(CLI),显示WSL的提示符 (`alex@zicode:~$`),以及执行Python代码和调用CUDA库(如 `torch.cuda.is_available()`)的代码片段。
* **右侧屏幕:** 展示了一个关于AI工作流的流程图,包含“WSL”、“CUDA”、“models”等关键词,并描绘了从数据集到推理的完整“AI Pipeline”。
* **品牌/标识:** 桌面和笔记本上可见“ZiCode”字样。
3. 技术信息:
* **操作系统环境:** WSL (Windows Subsystem for Linux),表明在Windows环境下运行Linux开发环境。
* **计算平台:** CUDA,NVIDIA的并行计算架构,用于加速深度学习和高性能计算。
* **编程语言/框架:** Python(通过终端执行),涉及PyTorch等深度学习库的概念。
* **主题流程:** AI Pipeline (人工智能流水线),涵盖数据集处理、模型训练、推理等完整机器学习生命周期。
* **硬件焦点:** GPU计算和性能监控。
4. 适合用途:
* 科技博客文章(关于AI开发环境搭建)。
* 技术教程或指南(如“如何在Windows上配置高性能的深度学习工作站”)。
* 产品宣传材料(用于推广NVIDIA、WSL或特定编程工具链)。
* 学术论文配图(展示实验环境和计算流程)。
5. 不确定点:
* 代码是否成功运行,以及当前模型训练的具体状态。
* 图片中显示的GPU型号的详细信息(仅能看到概念图和指标)。
* “ZiCode”品牌或其与开发内容的具体关联性。这段结果不是完美的。比如它把某些屏幕内容理解得偏笼统,也把“产品宣传材料、学术论文配图”列进了适合用途,范围有点宽。但它抓住了图片的核心:本地开发环境、WSL、CUDA、GPU 监控、AI Pipeline。这就是本地多模态模型在文章工作流里的价值:先把画面里的信息粗读出来,再由人来判断哪些可以写进正文。
视频测试没有直接把视频文件传给模型,而是先做抽帧。这次用的是一个真实的 26.8 秒竖屏视频,编码是 HEVC,分辨率 720x1280,带音频。原视频后半段有多处清晰人物合影,不适合作为公开样例,所以这次只从前半段筛选花草、纪念牌、环境和座位牌等低隐私帧。这样做会损失一部分叙事信息,但更适合写进公开文章。
下面是这次送给模型的 6 张抽帧拼图。它能让读者先看到模型“看见了什么”,再判断后面的模型输出是否可信。这里刻意没有选择清晰人物帧。

单帧也放出来,避免拼图压缩后看不清文字和细节。

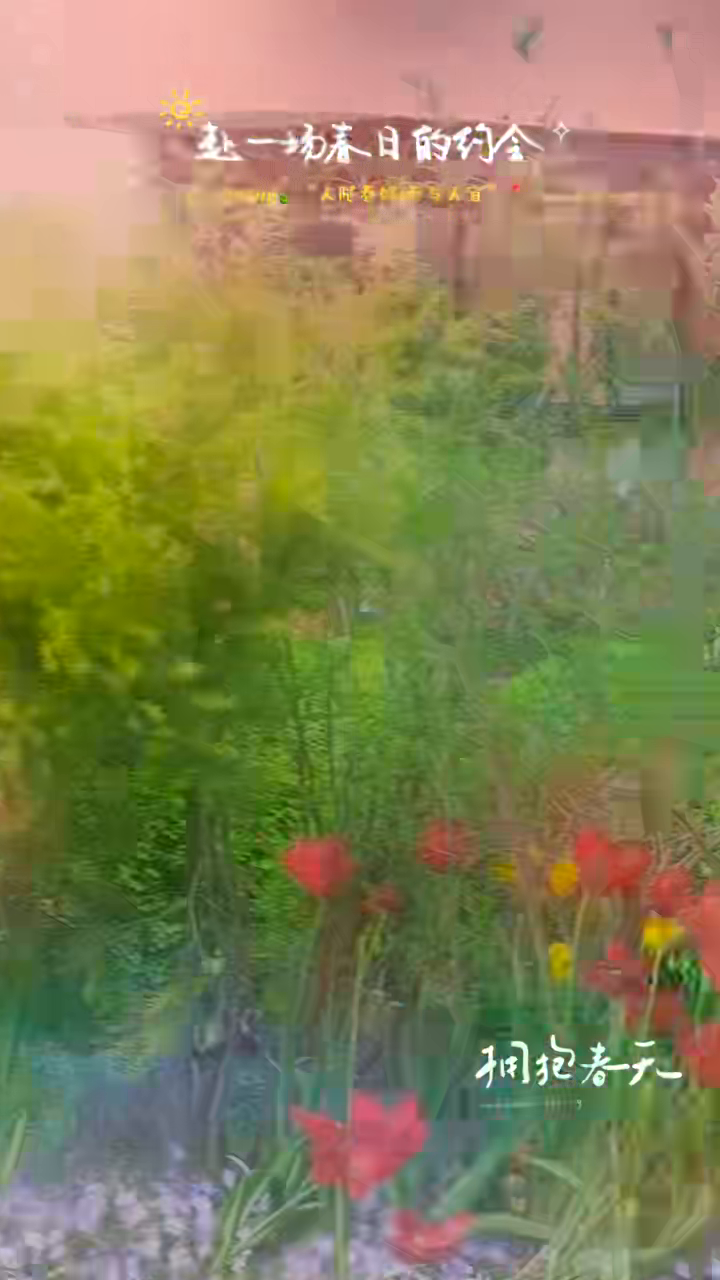
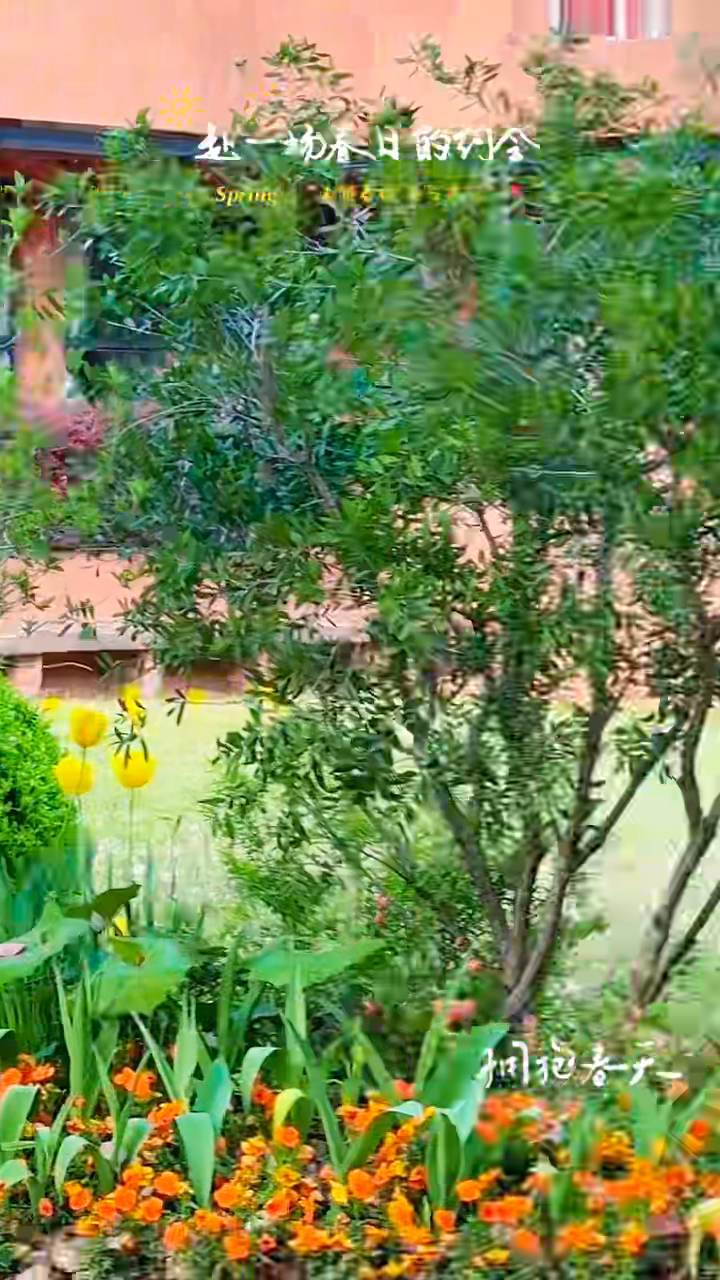



抽帧命令如下:
for ts in 0 3 4 6 9 11; do
ffmpeg -y -ss "$ts" -i 3.mp4 -frames:v 1 \
-vf 'scale=720:1280:force_original_aspect_ratio=decrease,pad=720:1280:(ow-iw)/2:(oh-ih)/2' \
"frame-${ts}.png"
done视频抽帧测试使用的完整 prompt 是:
这些图片是从同一个 26 秒竖屏视频中按时间顺序抽取的 6 张关键帧。为了降低隐私暴露,抽帧时刻刻意避开了清晰人物合影,只保留花草、纪念牌、环境和座位牌等画面。请基于这些帧做视频理解,按下面格式输出:
1. 视频主题:一句话概括这个视频在讲什么。
2. 画面内容:逐帧说明每一帧里能看到的主要内容。
3. 时间线:说明画面从开头到结尾大致发生了什么变化。
4. 文字信息:如果画面里有可读文字,请尽量识别并说明其作用;不确定的文字要标注“不确定”。
5. 适合用途:判断这段视频适合放进什么文章或场景。
6. 局限:只根据这些避开人物的抽帧理解,明确说明哪些信息无法确认。
请不要编造帧中看不到的信息。这是 gemma4:e4b 返回的原始结果文本。除了 Markdown 标题和列表外,我没有改写内容:
好的,我将根据您提供的六张关键帧图片,按照要求的格式进行视频内容分析。
---
### 视频分析报告
**1. 视频主题:**
纪念和记录一个充满春日气息的、与“思源”相关的周年庆典或校园活动。
**2. 画面内容(逐帧说明):**
* **第 1 帧 (第一张图):** 户外环境,背景虚化,光线明亮,顶部有太阳图案装饰。底部中央偏右方是文字信息和Logo。
* **第 2 帧 (第二张图):** 户外花海场景,前景有盛开的红色花朵(如罂粟花),背景是绿色的植被和建筑物的模糊轮廓。顶部有文字装饰。
* **第 3 帧 (第三张图):** 广阔的户外花园/校园场景,可以看到成片的黄色和橙色花卉(可能是水仙或类似花朵),环境开阔,光线柔和。底部有文字信息。
* **第 4 帧 (第四张图):** 近景特写,展示了固定在树干上的纪念牌。纪念牌上有清晰的文字内容,并用红色丝带装饰。背景是绿色的植被。
* **第 5 帧 (第五张图):** 户外环境,拍摄角度较低,前景有盛开的红花和绿色叶子,背景能看到水面或空旷的区域,光线明亮。顶部有文字装饰。
* **第 6 帧 (第六张图):** 室内/教学区域的特写,展示了固定在柜子或设备上的纪念牌。纪念牌上有清晰的周年庆典信息和年份。背景是相对简洁的内部环境。
**3. 时间线(画面变化):**
视频从一个泛景、充满春日氛围的开场(第 1 帧)开始,随后通过不同角度展示了校园内的花卉景观(第 2 帧 $\rightarrow$ 第 3 帧),重点聚焦于纪念意义的物品——首先是树上的周年纪念牌(第 4 帧),接着在更广阔的花海中记录美好瞬间(第 5 帧),最后收尾于一个室内或特定区域的设备上展示了另一个关键的周年纪念铭牌(第 6 帧)。整体节奏是从环境氛围铺垫 $\rightarrow$ 景观展示 $\rightarrow$ 核心纪念物特写,层层递进。
**4. 文字信息:**
* **贯穿始终的文字/Logo:** “一起来春天”、“思源 Spring”(此为活动或机构名称标识)。
* **第 2、3、5 帧(顶部):** “一起来春天” / “思源 Spring”。
* **第 4 帧(纪念牌):**
* “十草树”、“三十而立”、“滕人”、“南大”、“1996届计算机系3312班”、“毕业三十周年纪会”、“二〇二六年四月”(核心信息:纪念某届学生毕业三十周年)。
* **第 6 帧(纪念牌):**
* “庄梓铭初心 思源传新大”、“百年历程 同窗共致远”、“1996届计算机系3312班”、“毕业三十周年纪会”(核心信息:与第 4 帧内容高度一致,再次强调了纪念和时间节点)。
**5. 适合用途:**
* **学校/学院的校友回访视频:** 特别是为“思源”相关的学子或师生制作的怀旧、周年庆典回顾片。
* **毕业季宣传片:** 用于纪念特定届次的优秀毕业生和深厚的校园情谊。
* **活动预热/回顾素材:** 适用于在社交媒体(如朋友圈、视频号)发布,营造温馨、怀旧的氛围。
**6. 局限:**
由于所有画面都刻意避开了人物合影,因此无法确认以下关键信息:
* 参与活动的具体人员是谁(除了通过纪念牌推测出是1996届计算机系3312班的校友)。
* 视频的叙事重点是“周年庆典”本身,而非某个特定事件。
* 视频的情绪基调和高潮点无法从人物互动中捕捉到。这次输出有三个值得记录的点。第一,模型能在没有人物合影的情况下,仍然判断出视频大致是春日、校园、周年纪念这一类主题。第二,它能按帧描述画面变化,并意识到“避开人物合影”会限制对参与者和情绪高潮的判断。第三,它对文字识别仍然不稳定,比如纪念牌上的部分中文存在误读。视频抽帧理解可以用来做初筛、摘要和素材整理,但涉及文字识别时,最好再用 OCR 或人工复核。
这里要把边界说清楚:这次验证的是“视频抽帧理解”,不是直接把视频文件丢给模型做原生视频解析。对本地工作流来说,这已经很有用,因为很多视频摘要、屏幕录制理解、教程片段分析,本来就可以先按时间间隔抽帧,再交给视觉模型总结。
不过,这个测试也暴露了一个现实问题:多帧输入会明显变慢。这次 6 帧低隐私输入总耗时约 79 秒,eval_count=974。它适合做离线摘要、文章素材检查、屏幕录制初筛,不适合做实时视频助手。
我对这两个模型的定位是:
gemma4:e4b:默认图像理解模型,用来读截图、看图表、生成图片说明、检查文章配图是否跑题。gemma4:e4b+ 抽帧:视频摘要和屏幕录制初筛,用来判断主题、节奏和关键画面。gemma4:12b:复杂图片的二次分析模型,用来补充细节、做更完整的视觉解释。
需要注意的是,gemma4:e4b 在 raw:true 纯文本模式下表现正常,但 raw:true 加图片时失败过。对多模态任务,后续应该优先使用 /api/chat,并显式传 think:false。
llama.cpp 先作为基线
这次也用 llama.cpp 跑了一个 CPU 基线。Ollama 下载的 Qwen3 4B 模型底层是 GGUF,可以直接被 llama.cpp 识别。llama-bench 的结果大概是:
| 模型 | 后端 | 线程 | Prompt 处理 | 生成 |
|---|---|---|---|---|
| Qwen3 4B Q4_K_M | CPU | 16 | 约 4.5 tok/s | 约 12.4 tok/s |
这个结果只能说明一件事:CPU 能跑,但不是这台机器上最值得依赖的路线。
Ollama 调用同一个级别的小模型时,可以稳定跑到几十 tok/s;CPU 版 llama.cpp 则更适合作为兼容性验证。
这篇文章第一次写到这里时,CUDA 版 llama.cpp 还没有跑通。机器本身能看到 RTX 4060 Laptop GPU,Ollama 也已经在 WSL 里用上 GPU;但用下面的配置命令尝试打开 GGML_CUDA 时,CMake 会停在 CUDA Toolkit 检查阶段:
cmake -S ~/opt/llama.cpp \
-B ~/opt/llama.cpp/build-cuda \
-DCMAKE_BUILD_TYPE=Release \
-DGGML_CUDA=ON关键报错是:
Unable to find cudart library.
CUDA Toolkit not found后来我用 micromamba 在用户目录里补了一套 CUDA 12.4、GCC 13 和 cuBLAS 环境,已经把 CUDA 版 llama.cpp 编译起来了。完整过程单独写在《在 WSL 里把 llama.cpp CUDA 版编译起来:一次真实的本地部署记录》。同一份 Qwen3 4B GGUF 在 CUDA 版 llama-bench 下,tg32 约 78.7 tok/s;之前 CPU 版约 12.4 tok/s。
我的默认模型路由
跑完这轮以后,我不会把四个模型平铺给自己选,而是会做一个简单路由:
| 场景 | 默认模型 | 原因 |
|---|---|---|
| 短文本分类、标题、摘要 | qwen3:4b | 快,显存占用低 |
| 日常中文问答和代码解释 | qwen3:8b | 稳定性和速度比较平衡 |
| 截图理解、图片说明 | gemma4:e4b | 多模态可用,速度好 |
| 视频摘要、屏幕录制初筛 | gemma4:e4b + ffmpeg 抽帧 | 本地可控,不依赖原生视频解析 |
| 复杂图片细节复核 | gemma4:12b | 描述更细,但只适合按需调用 |
这比“哪个模型最强”更贴近日常。个人机器的目标不是把榜单第一名塞进显存,而是让不同任务都有足够快、足够稳、成本足够低的默认选择。
下一篇测什么
单纯跑分只能回答“能不能跑”和“快不快”。真正决定本地模型有没有价值的,是它能不能进入真实工作流。
所以下一篇会把这几个模型放进更具体的场景:开发日志解释、截图理解、文章配图审核、短文档摘要、结构化信息抽取。重点不是炫模型,而是看它们能不能在每天都要做的小任务里节省时间,并且不把流程变复杂。