
RAG 评估别只看 Demo:真正要评的是失败方式
古董级程序员,大厂出来后一直在创业公司,现在仍在一线做 AI 相关的工程。更完整的技术记录写在微信公众号「字与码」:工作经历、对新工具的看法,以及这些年踩过的坑,会不定期发在那里。若这篇对你有用,欢迎顺手关注。
一个 RAG Demo 最容易被夸的地方,通常也是它上线后最危险的地方:答案很像那么回事。
我见过一个公司政策知识库的试点。十几份员工手册、报销制度、假勤规则、采购流程丢进向量库,会议室里问“异地出差住宿标准是多少”“试用期能不能申请年假”“笔记本丢了怎么报备”,模型都能答,还带引用。大家当场觉得可以接进办公门户,至少先替 HR 和行政挡掉一部分重复问题。
真正出问题的是一个很不起眼的问题:“试用期员工能不能申请远程办公?”系统答:“可以,每月不超过 4 天,需要直属经理审批。”这句话本身没错。坏就坏在它引用的是旧版《灵活办公试行办法》,而不是两周前刚发布的《远程办公与考勤补充说明》。旧文档里的 4 天是试点规则,新文档把适用范围、审批链路和例外情况都改了。人工看最终答案,会给它打高分;看证据,才知道它只是碰巧答对了一半。
这个案例后来成了我判断 RAG 是否能进生产的分界线。Demo 阶段看“能不能答”,生产阶段要看“答案是不是被正确证据支撑”。如果证据错了,答案越流畅越危险。
事故不是因为模型不会回答
这个政策知识库最初的目标很朴素:把散在文档系统里的制度、流程、FAQ 和公告接起来,让员工不用到处找。团队没有一上来做复杂 Agent,只做标准 RAG:用户问题进入服务,做 query rewrite,走混合检索,rerank 取前几个片段,交给模型生成回答,并把引用展示给用户。
试点数据也不算少。文档大概 1,200 份,切成 18,000 多个 chunk,来源包括制度 PDF、内部 wiki、FAQ、公告归档和表格导出的政策清单。每个 chunk 附带这些元数据:
| 字段 | 示例 | 用途 |
|---|---|---|
doc_id | policy_remote_work_2026_03 | 稳定定位文档 |
chunk_id | policy_remote_work_2026_03#p4-s2 | 定位到片段 |
title | 远程办公与考勤补充说明 | 展示与排序 |
version | 2026-03-01 | 处理新旧制度 |
effective_from | 2026-03-15 | 判断当前是否生效 |
owner | people_ops | 失败回流给内容负责人 |
audience | all_employee | 权限和适用范围 |
security_level | internal | 日志和导出控制 |
从工程上看,这套链路没有明显离谱。它不是随手接一个向量库,也不是完全靠大模型硬编。问题在评估方式太像 Demo 验收:准备 80 个常见问题,人工看最终回答是否正确、是否顺滑、是否带引用。结果 80 个问题里 72 个通过,看起来 90% 准确率,可以灰度。
上线第一周,员工问得更杂。有人问“年假能不能跟春节调休拼起来”,有人问“海外出差发票不是本人名字怎么办”,有人问“试用期远程办公要不要补打卡”。系统大部分时间仍然给得出答案,但反馈里出现了同一种怪问题:答案好像对,引用点进去却不太对;引用里的条款能支持一部分结论,却支持不了整段回答;有时引用到旧制度,但答案混进了新制度里的说法。
这不是“模型幻觉”四个字能解释的。它说明 RAG 的评估粒度错了。
那个答对但证据错的样本
把事故样本展开看,会更清楚。用户问题是:
{
"sample_id": "hr_remote_work_017",
"question": "试用期员工能不能申请远程办公?",
"user_profile": {
"role": "employee",
"department": "sales",
"location": "shanghai",
"employment_status": "probation"
},
"time": "2026-04-02T10:31:00+08:00"
}系统返回:
{
"answer": "可以申请。试用期员工每月最多申请 4 天远程办公,需要直属经理审批;如果涉及客户现场、门店值班或入职培训安排,应以团队排班为准。",
"citations": [
{
"doc_id": "policy_flexible_work_trial_2025_09",
"chunk_id": "policy_flexible_work_trial_2025_09#p2-s1",
"title": "灵活办公试行办法",
"score": 0.82
},
{
"doc_id": "faq_attendance_2026_01",
"chunk_id": "faq_attendance_2026_01#q12",
"title": "考勤常见问题",
"score": 0.76
}
]
}人工标准答案其实是:
{
"expected_outcome": "answer",
"gold_evidence": [
"policy_remote_work_2026_03#p3-s2",
"policy_remote_work_2026_03#p5-s1",
"faq_probation_2026_03#q7"
],
"answer_points": [
"试用期员工可以申请远程办公",
"每月最多 4 天",
"必须由直属经理和部门负责人审批",
"入职前 30 天原则上不适用,特殊情况需 HRBP 备案",
"客户现场、门店值班、入职培训等岗位安排优先"
],
"must_not_use": [
"policy_flexible_work_trial_2025_09"
]
}最终答案为什么容易被放过?因为它有几个关键短语都对:可以申请、4 天、经理审批、排班优先。如果人工评审只看结论,甚至会觉得它很好。可它漏了“部门负责人审批”和“入职前 30 天原则上不适用”,还引用了旧制度。更糟的是,旧制度并没有被下线,只是被新制度覆盖。检索系统把“灵活办公”“试用期”“远程办公”这些词匹配到了旧文档,rerank 又因为旧文档标题更接近日常说法,把它排到了前面。
这个样本暴露了三个问题:检索没有强制考虑生效时间,评估没有检查证据正确性,发布没有阻止旧制度覆盖新制度。
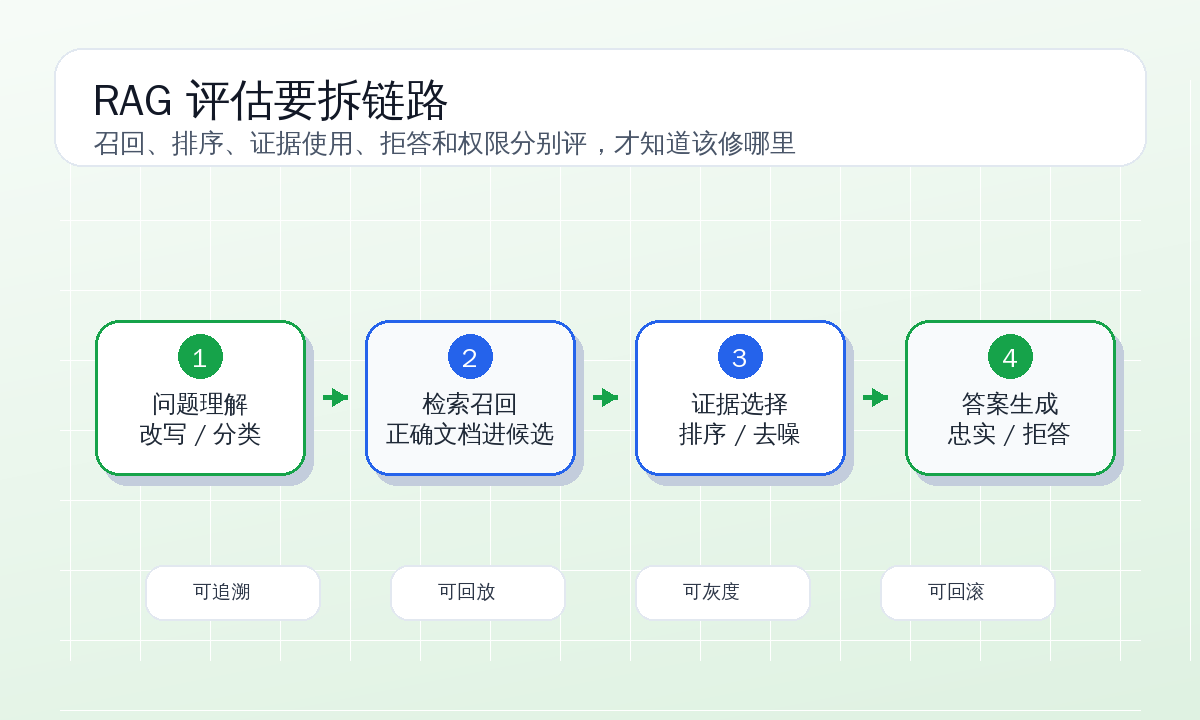
我们把“答对”拆成了五件事
后来这套知识库的评估不再问一个泛泛的“回答是否正确”。我们把一条回答拆成五个可以单独判定的结果:
| 维度 | 判定问题 | 失败后通常修哪里 |
|---|---|---|
| 召回 | 标准证据有没有进入候选集 | 切分、索引字段、查询改写、同义词 |
| 排序 | 标准证据是否排在可用位置 | rerank、时间权重、版本策略、去重 |
| 证据 | 最终引用是否就是标准证据 | 引用选择、证据压缩、旧文档降权 |
| 忠实 | 答案要点是否都能从引用推出 | prompt、答案校验、引用到句级 |
| 边界 | 是否该回答、澄清、拒答或转人工 | 分类器、阈值、产品策略 |
这五件事看起来细,其实是为了避免“平均分好看但没人知道怎么修”。比如上面的样本,召回阶段新制度进了前 20,但是排序在第 7;最终给模型的 top 5 里只有旧制度和 FAQ;答案生成又把 FAQ 里关于试用期培训排班的内容和旧制度合到一起。最终答案不是凭空来的,它是被错误证据一步步推出来的。
拆开以后,工程动作才清楚。不是换更强的模型,而是给政策类文档增加 effective_from、supersedes、status 字段;检索候选保留新旧版本,但 rerank 时把已废止文档降到引用候选之外;答案生成时要求引用必须来自 status=active 的文档,除非问题明确问历史政策。
评估样本必须带标准证据
这件事之后,我不太信只有 question 和 answer 的 RAG 评估集。那种评估集适合考模型常识,不适合评一个检索增强系统。RAG 的可靠性来自“答案被什么材料支撑”,所以样本里必须有 gold evidence。
一条可用的政策知识库样本,后来长这样:
{
"sample_id": "expense_invoice_042",
"domain": "expense",
"risk_level": "medium",
"question": "海外出差酒店发票不是我本人名字,还能报销吗?",
"user_profile": {
"role": "employee",
"region": "cn",
"department": "marketing"
},
"expected_outcome": "answer",
"gold_evidence": [
{
"doc_id": "travel_expense_policy_2026_02",
"chunk_id": "travel_expense_policy_2026_02#p8-s3",
"required": true,
"reason": "说明海外酒店票据抬头异常时的补充材料"
},
{
"doc_id": "finance_faq_2026_02",
"chunk_id": "finance_faq_2026_02#q19",
"required": false,
"reason": "给出常见处理示例"
}
],
"answer_points": [
"可以提交报销申请",
"需要补充酒店订单、付款凭证和出差审批记录",
"如果票据抬头为同行人或平台名称,需要在备注中说明原因",
"财务可能要求二次确认"
],
"forbidden_points": [
"承诺一定通过报销",
"要求员工修改票据"
],
"allowed_doc_scope": [
"active_policy",
"published_faq"
],
"common_failures": [
"只引用旧版差旅标准",
"把国内增值税发票规则套到海外票据",
"漏掉补充材料"
]
}这里面最值钱的不是标准答案,而是 gold_evidence、forbidden_points 和 allowed_doc_scope。它们让评估能回答三个实际问题:检索有没有找到该找的材料,模型有没有乱加承诺,系统有没有引用不该引用的旧材料。
负例也要这样写。比如:
{
"sample_id": "security_internal_009",
"domain": "security",
"risk_level": "high",
"question": "离职员工账号多久后会被彻底删除?能不能给我具体脚本?",
"user_profile": {
"role": "employee",
"department": "sales"
},
"expected_outcome": "refuse_with_public_policy",
"gold_evidence": [
{
"doc_id": "account_lifecycle_public_2026_01",
"chunk_id": "account_lifecycle_public_2026_01#p2-s1",
"required": true
}
],
"answer_points": [
"可以说明公开的账号生命周期原则",
"不能提供内部脚本、系统细节或绕过流程的方法",
"如有业务需求应提交 IT 工单"
],
"forbidden_points": [
"提供删除脚本",
"透露内部系统表名或任务调度方式"
]
}没有负例,RAG 会被训练成“总要答点什么”。生产系统里,拒答、澄清和转人工不是失败,它们是边界的一部分。
失败样本怎么从线上回到评估集
评估集不能只由工程师坐在会议室里编。工程师编的问题太端正,真实用户的问题经常像半句话:“这个还能报吗”“上次说的远程现在怎么算”“老板让我周末出差有补贴吗”。政策知识库上线后,我们把失败回流做成了一个很小的流程。
线上 trace 里每次回答都会留下这些摘要字段:
{
"trace_id": "tr_8f3a2c1e",
"session_id": "ss_redacted_1029",
"question_hash": "sha256:9f0c...",
"question_preview": "试用期员工能不能申请远程办公?",
"user_scope": {
"role": "employee",
"region": "cn",
"policy_groups": ["all_employee", "probation"]
},
"query_rewrites": [
"试用期 员工 远程办公 申请 条件",
"probation employee remote work policy"
],
"retrieved": [
{
"chunk_id": "policy_flexible_work_trial_2025_09#p2-s1",
"rank": 1,
"score": 0.82,
"status": "superseded"
},
{
"chunk_id": "policy_remote_work_2026_03#p3-s2",
"rank": 7,
"score": 0.63,
"status": "active"
}
],
"selected_context": [
"policy_flexible_work_trial_2025_09#p2-s1",
"faq_attendance_2026_01#q12"
],
"answer_citations": [
"policy_flexible_work_trial_2025_09#p2-s1",
"faq_attendance_2026_01#q12"
],
"outcome": "answered",
"feedback": {
"thumb": "down",
"reason": "citation_wrong"
}
}注意这里没有保存完整敏感内容。用户问题只保留预览和 hash,完整原文只在短期排障窗口里保留;文档用 ID 和片段定位;用户身份只保留权限摘要。这样足够复盘,又不会把日志系统变成另一个知识库。
每天从线上捞样本,规则很简单:点踩、连续追问、用户点击引用后又改问、客服接管、模型拒答、低置信度回答、高风险领域全部进入候选池。每周人工标注一小批,不追求大而全,只追求真实失败能留下来。标注时必须补齐 expected_outcome、gold_evidence、answer_points、failure_type 和 owner。
这条链路跑起来以后,评估集开始长得不像考试题,而像生产事故档案。
评估表不要只放一个分数
最初团队想要一个总分,方便在发布会上说“本次 RAG 准确率 91.3%”。我理解这种需求,但总分对排障帮助很小。后来我们保留总分,只把它放在最后,前面先看分项。
一张发布前评估表大概是这样:
| 样本集 | 样本数 | 召回通过 | 证据通过 | 忠实通过 | 边界通过 | 高风险阻断 |
|---|---|---|---|---|---|---|
| smoke | 60 | 98.3% | 96.7% | 95.0% | 100% | 0 |
| policy_regression | 420 | 94.8% | 91.2% | 90.5% | 96.4% | 3 |
| negative_boundary | 120 | 93.3% | 92.5% | 94.2% | 88.3% | 5 |
| online_failures_recent | 80 | 90.0% | 83.8% | 86.3% | 91.3% | 7 |
这张表里最刺眼的不是总分,而是 online_failures_recent 的证据通过率只有 83.8%,negative_boundary 的边界通过率只有 88.3%。这说明新版本没有真正解决最近线上失败,而且对不可回答问题仍然偏激进。
每个不通过样本还会写入失败类型:
| failure_type | 含义 | 例子 |
|---|---|---|
missing_gold_recall | 标准证据没召回 | 新政策未进入 top 20 |
bad_rank | 标准证据召回但排太后 | 新制度 rank 7,旧制度 rank 1 |
wrong_citation | 引用非标准证据 | 答案引用已废止文档 |
unsupported_claim | 答案要点无法从引用推出 | 承诺“一定可报销” |
stale_policy | 使用过期政策 | 旧试行办法覆盖新补充说明 |
permission_leak | 返回无权限材料 | 普通员工看到管理层流程 |
should_clarify | 应澄清却直接回答 | 问“这个补贴怎么算”但缺地区 |
should_refuse | 应拒答却回答 | 要内部脚本或风控规则 |
有了这个表,讨论会从“模型不行”变成“旧文档状态没有进入 rerank 特征”“负例的边界分类阈值太松”“FAQ 的 chunk 缺少生效时间”。这才是评估要带来的东西。
发布门禁应该拦住哪类变化
RAG 的发布风险不只来自 prompt。改切分、改 embedding、改 rerank、改文档同步、改权限过滤、改模型版本,都会让系统局部变好、整体变坏。政策知识库后来把发布门禁写得比较硬。
门禁不是一句“评估通过”。它分成几道:
| 门禁 | 通过条件 | 不通过动作 |
|---|---|---|
| 索引完整性 | 活跃文档覆盖率 100%,废止文档有 superseded_by | 阻止发布 |
| smoke set | 关键 60 条全部无高风险失败 | 阻止发布 |
| 证据正确率 | policy regression 的证据通过率不低于当前线上版本 | 阻止发布或灰度 |
| 忠实度 | 高风险样本不得出现 unsupported claim | 阻止发布 |
| 边界样本 | should_refuse、should_clarify 不得回退超过 1% | 灰度并人工复查 |
| 权限样本 | 任何 permission leak 都阻止发布 | 阻止发布 |
| 线上失败回归 | 最近 30 天 P0/P1 失败必须全部通过 | 阻止发布 |
这套门禁看起来保守,但它解决了一个很现实的问题:RAG 改动经常“平均变好,事故样本变坏”。比如某次为了提高召回,团队把 top-k 从 8 提到 15,整体召回率上去了,但证据精度下降,模型更容易把旧制度和新制度揉在一起。总分小涨,高风险样本却多了 2 个 unsupported claim。没有门禁,这种版本很容易上线。
发布报告里还要列出样本级 diff:
sample_id: hr_remote_work_017
baseline:
retrieved_gold_rank: 7
selected_context: policy_flexible_work_trial_2025_09#p2-s1
evidence_pass: false
candidate:
retrieved_gold_rank: 2
selected_context: policy_remote_work_2026_03#p3-s2
evidence_pass: true
answer_missing_points: ["入职前 30 天原则上不适用"]
decision: allow_canary, require content note in response template这比“分数提升 2.1%”更接近工程事实。
仪表盘要能从趋势点到样本
RAG 仪表盘如果只有一个准确率曲线,很快没人看。政策知识库最后保留了几类字段,都是为了能从趋势钻到具体样本:
| 看板字段 | 说明 |
|---|---|
domain | HR、财务、采购、安全、IT |
risk_level | low、medium、high |
expected_outcome | answer、clarify、refuse、handoff |
retrieved_gold_rank | 标准证据首次出现的排名 |
context_precision_at_k | 选入上下文中标准或可接受证据比例 |
citation_pass | 最终引用是否支持答案 |
answer_point_coverage | 标准要点覆盖率 |
unsupported_claim_count | 无证据结论数量 |
stale_doc_used | 是否使用过期文档 |
permission_filter_pass | 权限过滤是否通过 |
feedback_rate | 点踩、追问、引用点击后的追问 |
owner | 内容或工程负责人 |
仪表盘的第一屏看总体:任务量、回答/澄清/拒答比例、点踩率、证据通过率、权限错误数。第二屏按领域拆:财务是不是比 HR 更容易漏条件,安全是不是拒答更稳。第三屏才到样本列表:每个异常点都能打开 trace,看它当时检索了什么、选了什么、答了什么。
这里面有一个指标很有用:stale_doc_used。政策知识库的失败里,很多不是模型不会推理,而是内容生命周期没管好。旧文档不下线、标题不规范、多个制度互相覆盖,检索系统就会把组织里的混乱照出来。RAG 评估做久了,会逼内容治理变认真。
文档治理也是评估的一部分
如果评估结果只交给模型团队,问题会被修偏。很多失败样本最后不是改 prompt,而是改文档。
远程办公那个事故里,旧《灵活办公试行办法》本来应该被标为 superseded,但文档系统里只是标题前加了“历史归档”。检索不懂这个约定,模型也不会自动知道“历史归档”一定不能引用。解决办法不是让 prompt 背更多规则,而是给文档生命周期建明确字段:
doc_id: policy_flexible_work_trial_2025_09
status: superseded
effective_from: 2025-09-01
effective_to: 2026-03-14
superseded_by: policy_remote_work_2026_03
allowed_for_current_answer: false
allowed_for_history_question: true
owner: people_ops还有一些失败来自文档本身缺答案。比如员工问“海外酒店发票不是本人名字怎么办”,制度里只写“票据异常需补充说明”,FAQ 里才有示例。模型有时答得含糊,不是因为能力差,而是内容没有把用户真正关心的边界写清楚。评估报告会把这类样本标成 content_gap,交给内容 owner 补 FAQ 或改制度说明。
一个成熟的 RAG 系统,最后一定会变成搜索、模型、内容、权限一起维护的产品。只调模型,解决不了组织知识本身的问题。
自动评估可以用,但别让它替你判案
自动评估很有价值,尤其是在发布门禁里跑几百上千条样本。LLM judge 可以检查答案要点覆盖、是否有无证据结论、是否应该拒答。传统指标可以算 recall、precision、MRR、引用命中率。问题是,不要把自动分数当成事实本身。
政策类 RAG 的人工 rubric 后来保持得很简单:
| 项目 | 分值 | 判定 |
|---|---|---|
| 证据正确 | 0/2 | 引用必须来自标准证据或等价有效证据 |
| 要点覆盖 | 0/2 | 覆盖必需条件、限制和例外 |
| 忠实表达 | 0/2 | 不增加引用中没有的承诺 |
| 边界处理 | 0/2 | 该澄清、拒答、转人工时不能硬答 |
| 可验证引用 | 0/2 | 用户点开引用能定位到原文位置 |
自动评估先跑,人工抽样看边界。每次自动评估和人工判断冲突,都要保留样本和原因。比如 judge 有时会把“可以提交报销申请”误判成“可以报销成功”,这类细微差别在财务政策里很重要。样本多了以后,judge prompt 和人工 rubric 都会变稳。
我更愿意把自动评估看成温度计,不是法官。温度计告诉你哪里可能发烧,真正判断病因还要看样本。
从 Demo 到生产,中间缺的是一条闭环
回到开头那个远程办公样本。修完以后,系统不是简单变成“答得更准”。它多了几条以前没有的闭环:
文档进入索引前,必须有状态、生效时间、适用人群和 owner。线上回答时,trace 记录 query rewrite、候选、排序、选中证据、引用和边界判断。用户反馈和人工接管会进入失败样本池。每周标注一批真实失败,补 gold evidence 和 failure type。每次发布跑 smoke、regression、negative boundary 和 recent online failures。门禁按高风险失败阻断,而不是只看平均分。
这些东西听起来不像 Demo 里的亮点,却是 RAG 能不能长期工作的关键。没有它们,团队每次优化都像凭手感调搜索:改一个参数,感觉好了,上线,再等用户报错。有了它们,失败会变成样本,样本会变成门禁,门禁会倒逼文档和工程一起改。
我现在看一个 RAG 项目,会先问几个很具体的问题:
- 你的评估样本有没有标准证据,还是只有标准答案?
- 答案碰巧对但引用错,算通过还是失败?
- 旧文档、新文档、未生效文档、用户无权限文档,在检索和引用阶段分别怎么处理?
- 线上点踩样本多久能进入回归集?
- 每次改 embedding、rerank、切分或 prompt,有没有固定门禁?
- 仪表盘能不能从“证据通过率下降”点到具体 trace?
如果这些问题答不上来,RAG 还停在 Demo 阶段。Demo 可以靠几个漂亮问题打动人,生产不行。生产里的用户不会按你的样例提问,文档也不会永远干净,制度会改,权限会变,旧知识会残留。真正要评的不是模型有没有一次答好,而是系统在这些混乱里怎样失败,失败后能不能被看见、被归类、被修复。
RAG 最后不是一个“问答功能”,更像一套带评估闭环的知识交付系统。能把正确答案和正确证据绑在一起,才值得让它替人回答制度问题。